一、需求分析
1.1、数据现状
- 每个
media可发布不同类型(微头条、文章、视频)的状态。 - 每种类型都是从独立的系统发布,数据存在不同的数据库,且都未分表分库。
- 当前
media主页只展示了微头条动态。用户关注feed也只加载了media的微头条动态。 media共有12.6w 个,其中有 297 个media有粉丝,最多一个有 567 位粉丝。- 有 1.8k 用户有关注
media,最多一个用户关注了 46 个media
1.2、展示需求
需求可总结为以下4个接口
1.2.1 个人主页接口
- 在
media主页统一展示各种类型动态
1.2.2 关注页接口
- 已关注, 展示所关注
media的所有动态 - 已关注, 查询所关注
media的新动态数量 - 未关注时,关注页展示数据
二、方案一:拉模式
拉模式是指,直接从各个来源拉取数据,再聚合排序截取。
- 优点:结构简单
- 缺点:直接请求数据库
以文章库测试,批量查询用户关注人的动态(in $media_id_list):关注1000人时,响应时间大概50ms;关注2000人时,响应时间大概70ms。
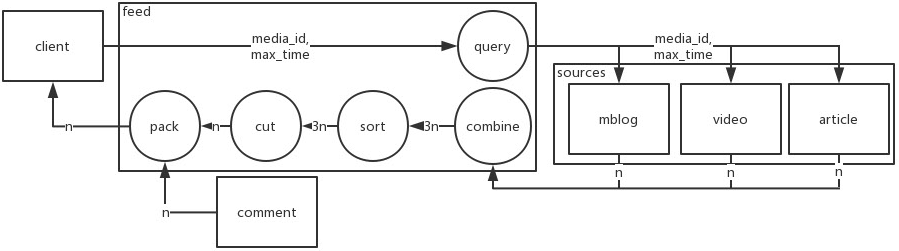
2.1、个人主页接口
2.1.1 在 media 主页统一展示各种类型动态
0)外部支持
需要各来源提供接口:
- 请求参数:
media_id,max_time,size - 返回:来源内容列表
- 说明:查找
media_id的,发布时间降序且小于max_time的,前size条来源内容列表
1)接口参数
media_id,max_time(可选,默认当前时间),size(可选,默认10,最大20)
2)执行流程
- 根据
media_id,max_time,去各来源,并发请求 n 条数据 - 对各来源返回的数据,根据发布时间排序,截取前 n 条
- 对这 n 条数据,请求评论信息,封装返回
2.2、关注页接口
2.2.0 前置准备
1)用户请求最新动态的时间
使用redis记录用户请求关注页最新动态的时间。key为time_mark:$user_id,value为$time_mark。
读取time_mark时若key不存在,则返回0,表示未读过。
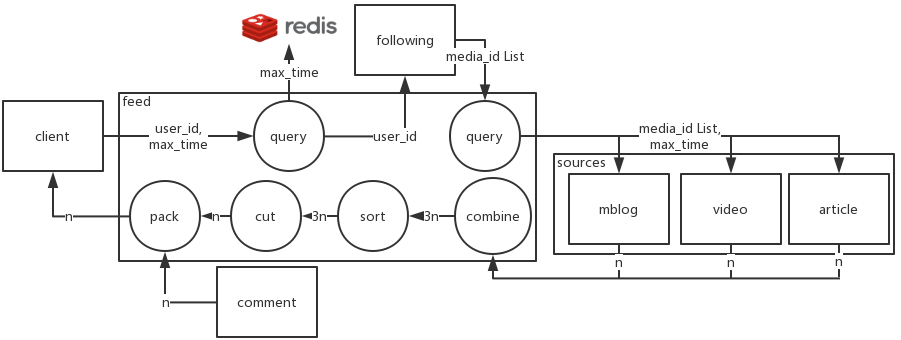
2.2.1 已关注,展示所关注 media 的所有动态
0)外部支持
需要各来源提供接口:
- 请求参数:
media_id list,max_time,size - 返回:来源内容列表
- 说明:查找
media_id list的,发布时间降序且小于max_time的,前size条来源内容列表
1)接口参数
user_id,max_time(可选,默认当前时间),size(可选,默认10,最大20)
2)执行流程
- 根据
user_id查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark。- 若
max_time大于time_mark,则使用max_time覆盖redis中的time_mark; - 若
max_time不大于time_mark,则跳过。
- 若
- 根据
media_id list,max_time,去各来源,并发请求 n 条数据 - 对各来源返回的数据,根据发布时间排序,截取前 n 条
- 对这 n 条数据,拼接分享信息,请求评论信息,封装返回
- 从
- 若用户没有关注,请看下面“2.2.3 章节”
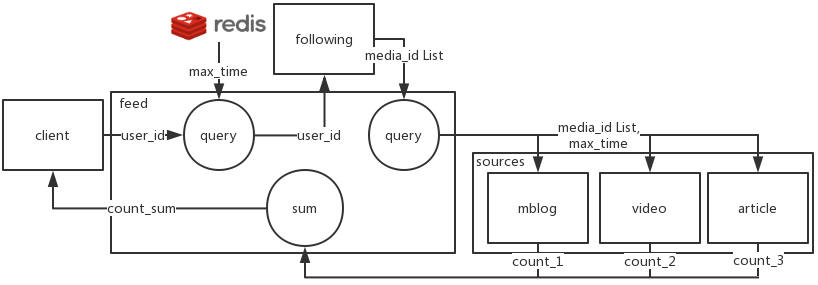
2.2.2 已关注,查询所关注 media 的新动态数量
0)外部支持
需要各来源提供接口:
- 请求参数:
media_id list,max_time - 返回:来源内容数量
- 说明:查找
media_id list的,发布时间降序且大于max_time的,来源内容数量
1)接口参数
user_id
2)执行流程
- 根据
user_id查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark - 根据
media_id list,time_mark,去各来源,并发请求动态数量 - 对各来源返回的数量,合并返回
- 从
- 若用户没有关注,返回 0
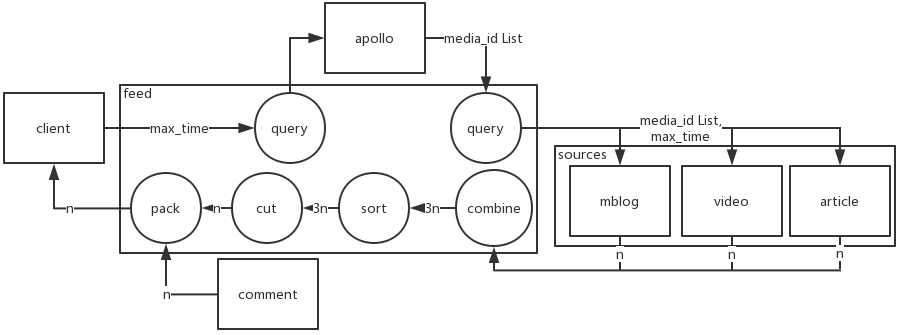
2.2.3 未关注时,关注页展示数据
用户未登陆或未关注任何media时,展示推荐media的数据。后台维护一个推荐media_id list。
1)接口参数
max_time(可选,默认当前时间)
2)执行流程
- 获取后台维护的推荐
media_id list - 根据
media_id list,max_time,去各来源,并发请求 n 条数据 - 对各来源返回的数据,根据发布时间排序,截取前 n 条
- 对这 n 条数据,请求评论信息,封装返回
三、方案二:拉模式进阶 - 集中模式
集中模式是指,将各来源的动态 id集中到一张feed 表。用户从feed 表批量获取动态 id,再根据动态 id去各来源请求动态内容。
- 优点:
- 从
feed 表表查询动态 id时已聚合排序,无需请求多余数据,也无需请求后再聚合排序。 - 数据库批量请求放在
feed 表,减轻来源系统的负担。
- 从
- 缺点:增加系统复杂度。需要维护数据库,接收 kafka 消息。
3.0、前置准备
3.0.1 新建 feed 表
mysql 新建 feed 表,记录每个用户发布的动态。
| 属性 | 类型 | 含义 |
|---|---|---|
| id | bigint | 主键 |
| media_id | bigint | 媒体id |
| source | int | 来源(1视频;2文章;3微头条) |
| source_id | bigint | 来源id |
| pub_time | bigint | 发布时间 |
唯一索引(source+source_id)
普通索引(media_id+pub_time)
普通索引(pub_time)
3.0.2 数据同步
0)外部支持
需要各来源在发布、删除动态后,发送 kafka 消息:
- topicId:
media-post-$source - value:
media_id,source_id,action_type,pub_time
1)历史数据
遍历所有 media,请求其各渠道已发布内容,插入到 feed 表
2)实时数据
Feed 系统监听 kafka 消息,并对feed 表进行增删。
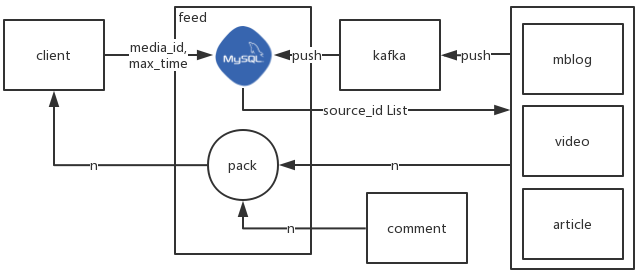
3.1、个人主页接口
3.1.1 在 media 主页统一展示各种类型动态
0)外部支持
需要各来源提供接口:
- 请求参数:
source_id list - 返回:来源内容列表
- 说明:对
source_id list,批量查询来源内容
1)接口参数
media_id,max_time(可选,默认当前时间),size(可选,默认10,最大20)
2)执行流程
- 根据
media_id,max_time,size从feed 表查询source_id list - 根据
source_id list从各来源查询来源内容(来源处有缓存) - 对来源返回的
来源内容,拼接分享信息,请求评论信息,封装返回
3.2、关注页接口
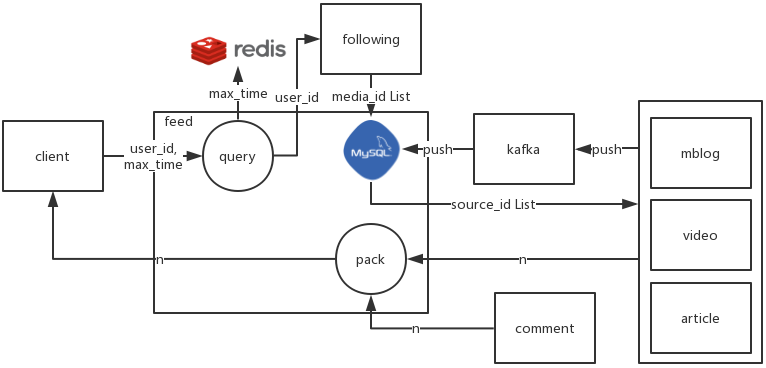
3.2.0 前置准备
1)用户请求最新动态的时间
使用redis记录用户请求关注页最新动态的时间。key为time_mark:$user_id,value为$time_mark。
读取time_mark时若key不存在,则返回0,表示未读过。
3.2.1 已关注,展示所关注 media 的所有动态
1)接口参数
user_id,max_time(可选,默认当前时间),size(可选,默认10,最大20)
2)执行流程
- 根据
user_id查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark。- 若
max_time大于time_mark,则使用max_time覆盖redis中的time_mark; - 若
max_time不大于time_mark,则跳过。
- 若
- 根据
media_id list,max_time,去feed 表,批量请求source_id list - 根据
source_id list从各来源查询来源内容(来源处有缓存) - 对来源返回的
来源内容,请求评论信息,封装返回
- 从
- 若用户没有关注,请看下面“3.2.3 章节”
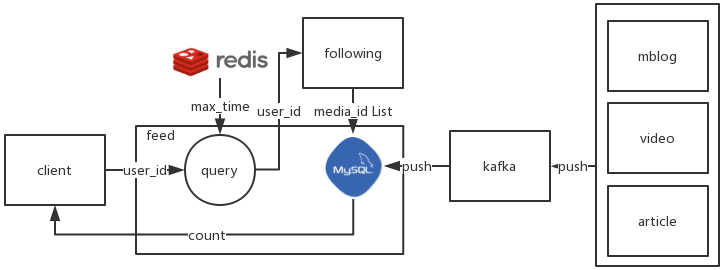
3.2.2 已关注,查询所关注 media 的新动态数量
1)接口参数
user_id
2)执行流程
- 根据
user_id查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark - 根据
media_id list,time_mark,去feed 表查询动态数量。返回
- 从
- 若用户没有关注,返回 0
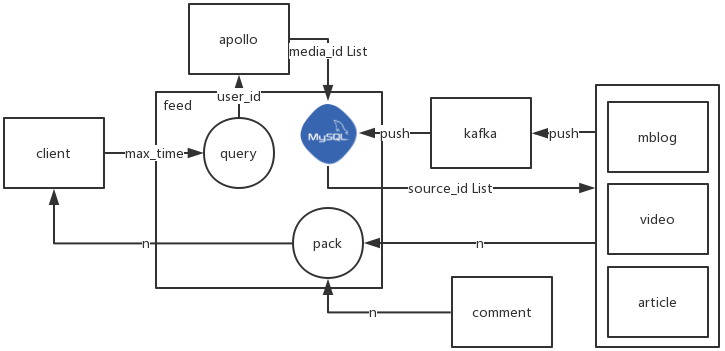
3.2.3 未关注时,关注页展示数据
用户未登陆或未关注任何media时,展示推荐media的数据。后台维护一个推荐media_id list。
1)接口参数
max_time(可选,默认当前时间)
2)执行流程
- 获取后台维护的推荐
media_id list - 根据
media_id list,max_time,去feed 表,批量请求source_id list - 根据
source_id list从各来源查询来源内容(来源处有缓存) - 对来源返回的
来源内容,请求评论信息,封装返回
四、方案三:推拉结合
针对“关注页接口”。若“内容来源表”或“feed 表”数据量增大后,批量请求(in $media_id_list)性能代价过大;或者分库分表了,无法批量请求,单个请求再聚合的性能代价过大。这时可以使用推模式。
推模式:为每个用户建立一个“收件箱”——follow_feed 表,media发布动态后,将动态给每个粉丝的“收件箱”都推送一条。用户查询“关注页接口”时,只需查询自己的“收件箱”,空间换时间。“关注页接口”读多写少,推模式在“写”的时候扩散数据,使读写更加平衡。
推拉结合:如果有大v(10万)存在,将大v的动态推送给所有粉丝时,代价也很大。这时可以推拉结合,区分大v小v,对少数的大v使用拉模式,只对多数小v推送。
- 优点:减轻读取数据时数据库压力
- 缺点:
- 需要大量额外空间
- 用户关注取关时,需要额外处理“收件箱”
4.0、前置准备
4.0.1 新建 follow_feed 表
mysql 新建 follow_feed 表,记录每个用户的关注对象发布的动态。
| 属性 | 类型 | 含义 |
|---|---|---|
| id | bigint | 主键 |
| user_id | bigint | 用户id |
| media_id | bigint | 媒体id |
| source | int | 来源(1视频;2文章;3微头条) |
| source_id | bigint | 来源id |
| pub_time | bigint | 发布时间 |
唯一索引(user_id+source+source_id)
普通索引(user_id+pub_time)
4.0.2 数据同步
0)外部支持
需要各来源在发布、删除动态后,发送 kafka 消息:
- topicId:
media_post:$source - value:
media_id,source_id,action_type
需要关注系统在用户关注、取关后,发送 kafka 消息:
- topicId:
follow_change - value:
media_id,user_id,action_type
1)历史数据
遍历所有media,请求其各渠道已发布内容,对每个粉丝插入到follow_feed 表
2)实时数据
Feed 系统监听 kafka media_post:$source消息。若media_id是大v则跳过。否则查询所有粉丝,结合每个粉丝的user_id对follow_feed 表进行增删。
Feed 系统监听 kafka follow_change消息。若media_id是大v则跳过。否则,关注时请求media_id的所有动态内容,结合user_id插入到follow_feed 表;取关时删除follow_feed 表中所有media_id+user_id的内容。
4.0.3 用户请求最新动态的时间
使用redis记录用户请求关注页最新动态的时间。key为time_mark:$user_id,value为$time_mark。
读取time_mark时若key不存在,则返回0,表示未读过。
4.1、关注页接口
4.1.1 已关注,展示所关注 media 的所有动态
1)接口参数
user_id,max_time(可选,默认当前时间),size(可选,默认10,最大20)
2)执行流程
- 根据
user_id从查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark。- 若
max_time大于time_mark,则使用max_time覆盖redis中的time_mark; - 若
max_time不大于time_mark,则跳过。
- 若
- 若用户有关注大v,(异步)对大v使用“方案一”或“方案二”请求
来源内容 - 根据
user_id,去follow_feed 表,批量请求source_id list - 根据
source_id list从各来源查询来源内容(来源处有缓存) - 对来源返回的
来源内容和大v查询的来源内容聚合排序截取,请求评论信息,封装返回
- 从
- 若用户没有关注,请看下面“4.1.3 章节”
4.1.2 已关注,查询所关注 media 的新动态数量
1)接口参数
user_id
2)执行流程
- 根据
user_id查询用户关注的media_id list - 若用户有关注
- 从
redis读取time_mark - 若用户有关注大v,(异步)对大v使用“方案一”或“方案二”请求动态数量
- 根据
user_id,time_mark,去follow_feed 表查询动态数量。 - 合并大v动态数量与普通动态数量,返回
- 从
- 若用户没有关注,返回 0
4.1.3 未关注时,关注页展示数据
用户未登陆或未关注任何media时,展示推荐media的数据。后台维护一个虚拟用户,关注推荐的media_id list,接口返回虚拟用户的关注页即可。
1)接口参数
max_time(可选,默认当前时间)
2)执行流程
通过虚拟用户的user_id和参数max_time,调用“4.1.1 章节”接口
五、总结
- 方案一:拉模式
- 优点:结构简单,能够快速实现
- 缺点:直接请求内容来源的数据库
- 适合:数据量较小
- 方案二:拉模式进阶 - 集中模式
- 优点:
- 减轻“来源系统”负担:数据库批量请求放在
feed 表。内容请求可以走“来源系统”的缓存。 - 减少网络传输:从
feed 表表查询动态 id时已聚合排序。
- 减轻“来源系统”负担:数据库批量请求放在
- 缺点:
- 增加系统复杂度。
- 需要维护数据库,接收 kafka 消息。
- 适合:数据量适中
- 优点:
- 方案三:推拉结合
- 优点:
- 读写均衡,减轻读取数据时数据库压力
- 支持分库分表
- 缺点:
- 系统复杂度最高
- 需要大量额外空间
- 需要额外处理用户的关注、取关
- 适合:数据量巨大
- 优点: