Spring Cloud Sleuth 分布式服务跟踪
快速入门
- pom依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
- 运行,控制台会输出请求链路
INFO [trace-1,f410ab57afd5c145,a9f2118fa2019684,false]
- 第一个值:应用名称
- 第二个值:Trace ID,Sleuth生成,标识请求链路。
- 第三个值:Span ID,Sleuth生成,表示一个基本的工作单元。
- 第四个值:是否抽象收集
- 收集和展示
链路日志都离散在各服务上,分析很麻烦,需要工具来集中的收集、存储和搜索这些跟踪信息。常用的有ELK的Logstash,还有Zipkin。
原理分析
跟踪原理
原理关键点:
- Trace ID
请求发送时,跟踪框架为该请求创建唯一跟踪标识,Trace ID ,同时在分布式系统内部流转保持唯一不变,直到收到返回。Trace ID将所有请求过程日志关联起来。 - Span ID
通过服务唯一标识Span ID,记录Span开始、具体过程以及结束,就能统计出该Span的时间延迟,统计各处理单元的时间延迟。
Spring Boot应用中,依赖spring-cloud-starter-sleuth之后,会自动为当前应用构建各通信通道的跟踪机制。比如:通过Stream消息中间件、Zuul代理传递、RestTemplate发起的请求。
收集原理
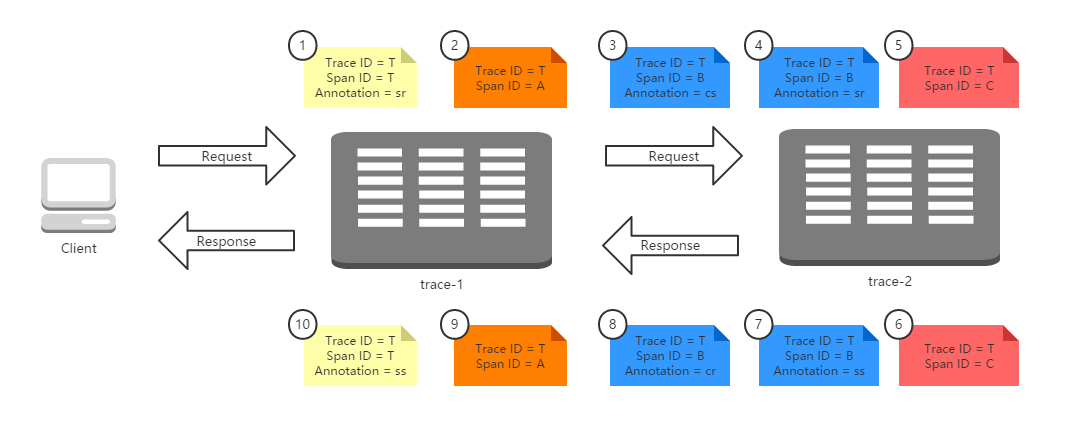
术语:
- Span
基础工作单元,一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解(tags),span处理者的ID(通常为IP)。 - Trace
包含一系列相同Trace ID的span,组成了一个树型结构 - Annotation
用于及时记录存在的事件,包含有时间戳的事件标签。四个核心Annotation:- cs - Client Sent:客户端发送一个请求,表示span的开始
- sr - Server Received:服务端接收请求并开始处理它。(sr-cs)等于网络的延迟
- ss - Server Sent:服务端处理请求完成,开始返回结束给服务端。(ss-sr)表示服务端处理请求的时间
- cr - Client Received:客户端完成接受返回结果,span结束。(cr-sr)表示客户端接收服务端数据的时间
- BinaryAnnotation
额外的补充说明,一般以键值对方式出现。
收集机制:
抽样收集
高并发的分布式系统运行时跟踪日志信息是海量的,如果收集过多,影响性能,浪费存储。Sleuth采用了抽象收集,为跟踪信息打上收集标记,代表是否被后续的跟踪信息收集器获取和存储。
Sleuth中的抽样收集策略是通过实现Sampler接口的isSampled方法,决定是否要被收集的标志。即使不收集,仍会跟踪。
抽样策略默认使用PercentageBasedSampler实现,以请求百分比的方式配置和收集跟踪信息。配置信息spring.sleuth.sampler.percentage=0.1。
整合Logstash
Logstash是ELK中的L,可以对日志进行收集、过滤,并将其存储供以后使用。
Spring Boot默认使用logback记录日志,Logstash自身有支持logback的工具,只需在logback的配置中增加对logstash的appender,就能将日志转换成Logstash需要的json的格式存储和输出。
- pom依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.6</version>
</dependency>
- 创建bootstrap配置文件,将
spring.application.name=trace-1配置移动到bootstrap,以期加载在logback-spring.xml之前。 - 创建logback配置文件
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- 日志在工程中的输出位置 -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- 控制台的日志输出样式 -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- 控制台Appender -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- 为logstash输出的json格式的Appender -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="logstash"/>
</root>
</configuration>
对logstash支持通过名为logstash的appender实现,主要是对日志信息的格式化处理。除了可以通过上面的方式生成json文件之外,也可以使用LogstashTcpSocketAppender将日志内容直接通过Tcp Socket输出到logstash服务端:
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>127.0.0.1:9250</destination>
...
</appender>
整合Zipkin
ELK的数据分析维度缺少对请求链路中各阶段时间延迟的关注,对于这样的问题,引入Zipkin可以轻松解决。
Zipkin源于Twitter,基于Google Dapper实现。Zipkin可以收集各个服务器上请求链路的跟踪数据,提供了REST API接口来查询跟踪数据,也提供了图形化界面。可通过http和消息中间件收集。
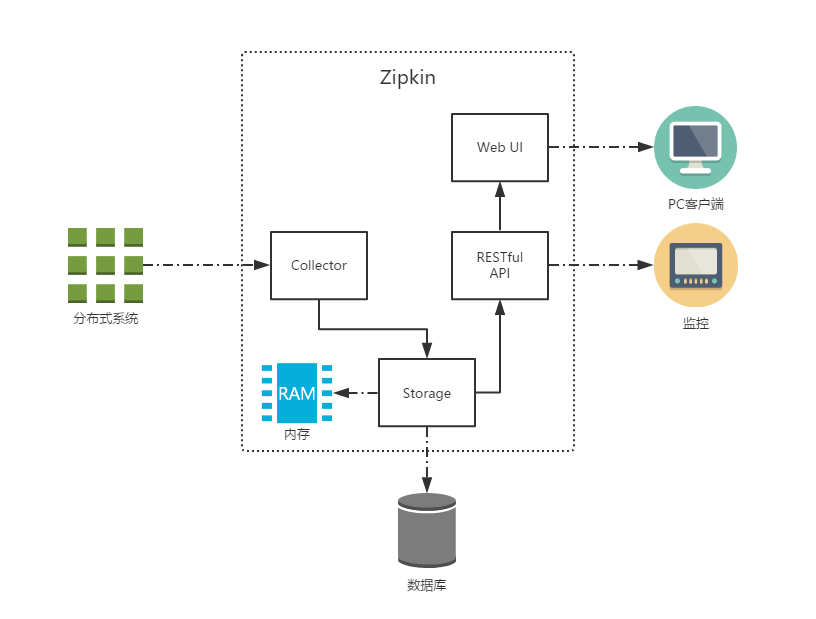
HTTP收集
搭建Zipkin Server
- pom依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
- @EnableZipkinServer注解启动类
- application配置
pring.application.name=zipkin-server
server.port=9411
启动访问localhost:9411可见Zipkin管理页面
应用配置Zipkin
对应用做一些配置,以实现将跟踪信息输出到Zipkin Server。
- pom依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
- application配置
spring.zipkin.base-url=http://localhost:9411
消息中间件收集
对http收集稍作修改可使用中间件收集
修改客户端
- pom依赖
除了需要之前引入的spring-cloud-starter-sleuth依赖之外,还需要引入zipkin对Spring Cloud Stream的扩展依赖spring-cloud-sleuth-stream以及基于Spring Cloud Stream实现的消息中间件绑定器依赖,以使用RabbitMQ为例
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
- application配置
去掉HTTP方式实现时使用的spring.zipkin.base-url参数,并根据实际部署情况,增加消息中间件的相关配置
修改服务端
- pom依赖
再引入针对消息中间件收集封装的服务端依赖spring-cloud-sleuth-zipkin-stream,针对消息中间件的绑定器实现,以使用RabbitMQ为例
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>