1 简介
HDFS 是 GFS(Google File System)的克隆版本。
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。
它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
2 HDFS架构
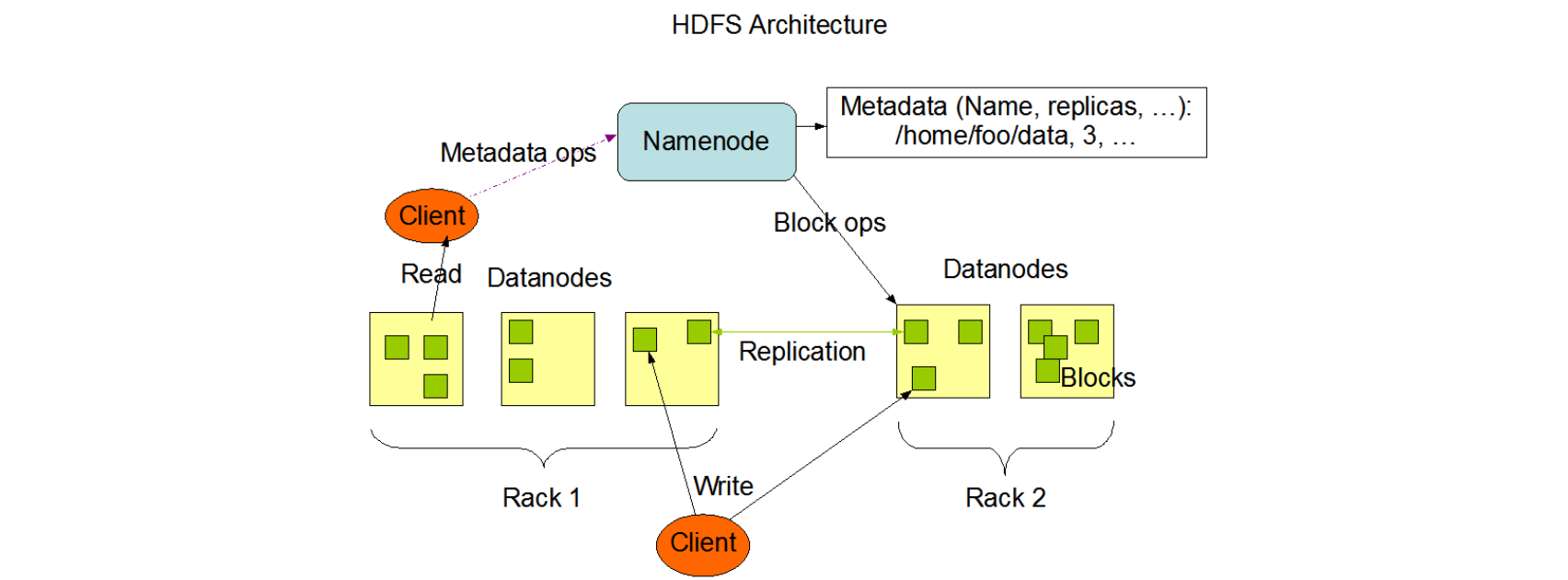
HDFS具有主/从结构。
1)NameNode
-HDFS集群包含单一的NameNode作为master服务器,用于管理文件系统命名空间,并调节客户端对文件的访问。
- 执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。
- 确定块到DataNodes的映射。
2)DataNode
集群中每个节点一个DataNode,管理连接到运行的节点的存储。
- 在内部,文件被分割成一个或多个块,存储在一组DataNodes中。
- 负责从文件系统的客户端提供读取和写入请求。
- 根据NameNode的指示执行块创建,删除和复制。
HDFS公开了文件系统命名空间,并允许将用户数据存储在文件中。
3 选择HDFS的原因
- 高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。
- 适合大数据处理
- 处理数据达到 GB、TB、甚至PB级别的数据。
- 能够处理百万规模以上的文件数量,数量相当之大。
- 能够处理10K节点的规模。
- 流式文件处理
- 一次写入,多次读取。文件一旦写入不能修改,只能追加。
- 它能保证数据的一致性。
- 可构建在廉价机器上
- 它通过多副本机制,提高可靠性。
- 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。