1 案例分析
1.1 高性能硬件上的程序部署策略
1)问题描述
- 一个每天 15 万 PV 左右的在线文档网站升级了硬件,4 个 CPU,16 GB 物理内存,操作系统为 64 位 CentOS 5.4,使用 Resin 作为 Web 服务器,没有部署其他的应用。
- 管理员选用了 64 位的 JDK 1.5,并通过 -Xmx 和 -Xms 参数将 Java 堆固定在 12GB。
- 使用一段时间不定期出现长时间失去响应的情况;
2)问题分析
- 升级前使用 32 位系统,Java 堆设置为 1.5 GB,只是感觉运行缓慢没有明显的卡顿;
- 通过监控发现是由于 GC 停顿导致的,虚拟机运行在 Server 模式,默认使用吞吐量优先收集器,回收 12GB 的堆,一次 Full GC 的停顿时间高达 14 秒;
- 并且由于程序设计的原因,很多文档从磁盘加载到内存中,导致内存中出现很多由文档序列化生成的大对象,这些大对象进入了老年代,没有在 Minor GC 中清理掉;
3)解决办法
- 在虚拟机上建立 5 个 32 位的 JDK 逻辑集群,每个进程按 2GB 内存计算(其中堆固定为 1.5GB),另外建议一个 Apache 服务作为前端均衡代理访问门户;
- 另外考虑服务压力主要在磁盘和内存访问,CPU 资源敏感度较低,因此改为 CMS 收集器;
- 最终服务没有再出现长时间停顿,速度比硬件升级前有较大提升;
1.2 集群间同步导致的内存溢出
1)问题描述
- 一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 小型机,服务器为 WebLogic 9.2,每台机器启动了 3 个 WebLogic 实例,构建一个6台节点的亲和式集群(一个固定的用户请求永远分配到固定的节点处理)。
- 由于有部分数据需要共享,原先采用数据库,后因为读写性能问题使用了 JBossCache 构建了一个全局缓存;
- 正常使用一段较长的时间,最近不定期出现了多次的内存溢出问题;
2)问题分析
- 监控发现,服务内存回收状况一直正常,每次内存回收后都能恢复到一个稳定的可用空间
- 此次未升级业务代码,排除新修改代码引入的内存泄漏问题;
- 服务增加 -XX:+HeapDumpOnOutOfMemoryError 参数,在最近一次内存溢出时,分析 heapdump 文件发现存在大量的 org.jgroups.protocols.pbcast,NAKACK 对象;
- 最终分析发现是由于 JBossCache 的 NAKACK 栈在页面产生大量请求时,有个负责安全校验的全局 Filter 导致集群各个节点之间网络交互非常频繁,当网络情况不能满足传输要求时,大量的需要失败重发的数据在内存中不断堆积导致内存溢出。
3)解决办法
- JBossCache 版本改进;
- 程序设计优化,JBossCahce 集群缓存同步,不大适合有频繁写操作的情况;
1.3 堆外内存导致的溢出错误
1)问题描述
- 一个学校的小型项目,基于 B/S 的电子考试系统,服务器是 Jetty 7.1.4,硬件是一台普通 PC 机,Core i5 CPU,4GB 内存,运行 32 位 Windows 操作系统;
- 为了实现客户端能实时地从服务器端接收考试数据,使用了逆向 AJAX 技术(也称为 Comet 或 Server Side Push),选用 CometD 1.1.1 作为服务端推送框架;
- 测试期间发现服务端不定期抛出内存溢出;加入 -XX:+HeapDumpOnOutOfMemoryError 后抛出内存溢出时什么问题都没有,采用 jstat 观察 GC 并不频繁且 GC 回收正常;最后在内存溢出后从系统日志发现如下异常堆栈:

2)问题分析
- 直接内存溢出的场景,垃圾收集时,虚拟机虽然会对直接内存进行回收,但它只能等老年代满了触发 Full GC 时顺便清理,否则只能等内存溢出时 catch 住然后调用 System.gc(),如果虚拟机还是不听(比如打开了-XX:+DisableExplictGC)则只能看着堆中还有许多空闲内存而溢出;
- 本案例中的 CometD 框架正好有大量的 NI O操作需要使用直接内存;
1.4 外部命令导致系统缓慢
1)问题描述
- 一个数字校园应用系统,运行在一个 4 个 CPU 的 Solaris 10 操作系统上,中间件为 GlassFish 服务器;
- 系统在做大并发压力测试时,发现请求响应时间比较慢,通过监控工具发现 CPU 使用率很高,并且系统占用绝大多数的CPU资源的程序并不是应用系统本身;
- 通过 Dtrace 脚本发现最消耗 CPU 的竟然是 fork 系统调用(Linux 用来产生新进程的);
2)问题分析
- 最终发现是每个用户请求需要执行一个外部的 shell 脚本来获取一些系统信息,是通过 Runtime.getRuntime().exec() 方法调用的;
- Java 虚拟机在执行这个命令时先克隆一个和当前虚拟机拥有一样环境变量的进程,再用这个新进程去执行外部命令,如果频繁地执行这个操作,系统消耗会很大;
- 最终修改时改用 Java 的 API 去获取这些信息,系统恢复了正常;
1.5 服务器 JVM 进程奔溃
1)问题描述
- 一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 系统,服务器是 WebLogic 9.2;
- 正常运行一段时间后发现运行期间频繁出现集群节点的虚拟机进程自动关闭的现象,留下一个 hs_err_pid###.log,奔溃前不久都发生大量相同的异常,日志如下所示:

2)问题分析
- 这是一个远端断开连接的异常,得知在 MIS 系统工作流的待办事项变化时需要通过 Web 服务通知 OA 门户系统;
- 通过 SoapUI 测试发现调用后竟然需要长达 3 分钟才能返回,并且返回结果都是连接中断;
- 由于 MIS 使用异步方式调用,两边处理速度不对等,导致在等待的线程和 Socket 连接越来越多,最终在超过虚拟机承受能力后进场奔溃;
3)解决方法
将异步调用修改为生产者/消费者模型的消息队列处理,系统恢复正常;
1.6 不恰当数据结构导致内存占用过大
1)问题描述
- 有一个后台 RPC 服务器,使用 64 位虚拟机,内存配置为 -Xms4g -Xmx8g -Xmn1g,使用 ParNew + CMS 的收集器组合;
- 平时 Minor GC 时间约在 20 毫秒内,但业务需要每 10 分钟加载一个约 80MB 的数据文件到内存进行数据分析,这些数据会在内存中形成超过 100 万个 HashMap Entry,在这段时间里 Minor GC 会超过 500 毫秒,这个时间过长,GC 日志如下:
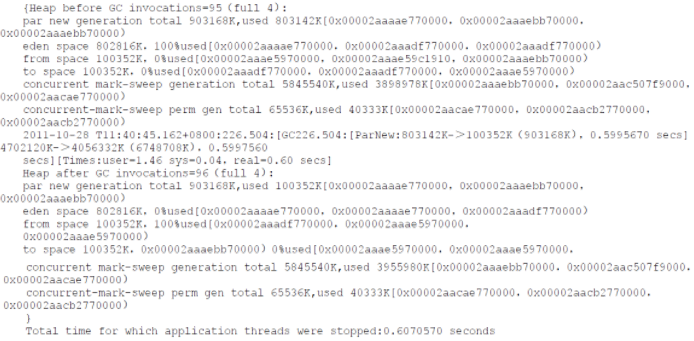
2)问题分析
- 在分析数据文件期间,800M 的 Eden 空间在 Minor GC 后对象还是存活的,而 ParNew 垃圾收集器使用的是复制算法,把这些对象复制到 Survivor 并维持这些对象引用成为沉重的负担,导致 GC 时间变长;
- 从 GC 可以将 Survivor 空间去掉(加入参数 -XX:SurvivorRatio=65536、-XX:MaxTenuringThreshold=0 或者 -XX:AlwaysTenure),让新生代存活的对象第一次 Minor GC 后立即进入老年代,等到 Major GC 再清理。这种方式可以治标,但也有很大的副作用。
- 另外一种是从程序设计的角度看,HashMap 结构中,只有 key 和 value 所存放的两个长整形数据是有效数据,共 16B(2 * 8B),而实际耗费的内存位 88B(长整形包装为 Long 对象需要多 8B 的 MarkWord、8B 的 Klass 指针,Map.Entry 多了 16B 的对象头、8B 的 next 字段和 4B 的 int 型 hash 字段、为对齐添加的 4B 空白填充,另外还有 8B 的 Entry 引用),内存空间效率(18%)太低。
1.7 由 Windows 虚拟内存导致的长时间停顿
1)问题描述
- 有一个带心跳检测功能的 GUI 桌面程序,每 15 秒发送一次心跳检查信号,如果对方 30 秒内都没有信信号返回,则认为和对方已断开连接;
- 程序上线后发现有误报,查询日志发现误报是因为程序会偶尔出现间隔约1分钟左右的时间完全无日志输出,处于停顿状态;
- 另外观察到 GUI 程序最小化时,资源管理中显示的占用内存大幅减小,但虚拟内存没变化;
- 因为是桌面程序,所需内存不大(-Xmx256m),加入参数 -XX:+PrintGCApplicationStoppedTime -XX:PrintGCDateStamps -Xloggc:gclog.log 后,从日志文件确认是 GC 导致的,大部分的 GC 时间在 100ms 以内,但偶尔会出现一次接近 1 min 的 GC;
- 加入参数 -XX:PrintReferenceGC 参数查看 GC 的具体日志信息,发现执行 GC 动作的时间并不长,但从准备开始 GC 到真正 GC 直接却消耗了大部分时间,如下所示:

2)问题分析
- 初步怀疑是最小化时工作内存被自动交换到磁盘的页面文件中,这样发生 GC 时就有可能因为恢复页面文件的操作而导致不正常的 GC 停顿;
- 在 MSDN 查证确认了这种猜想,加入参数 -Dsun.awt.keepWorkingSetOnMinimize=true 来解决;这个参数在很多AWT程序如 VisualVM 都有应用。
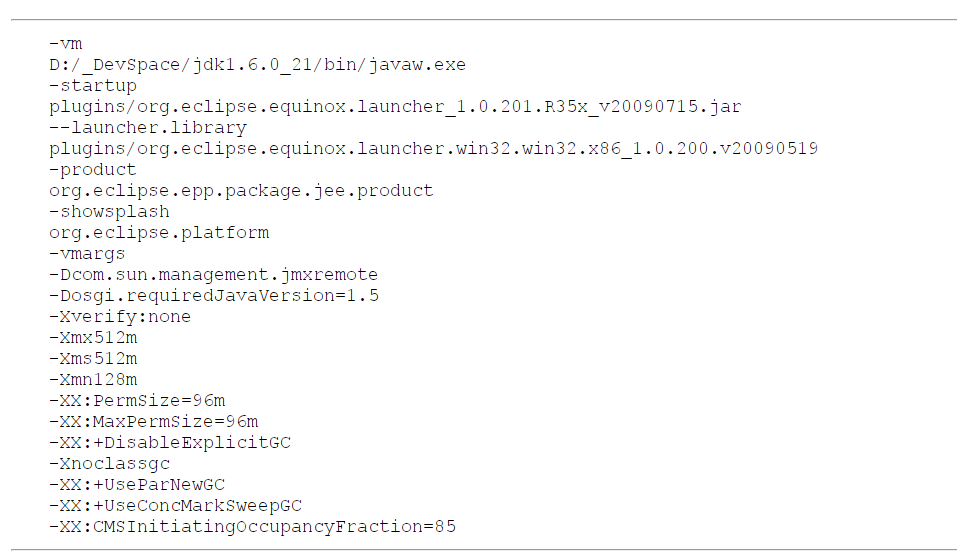
2 实战:Eclipse 运行速度调优
- 升级 JDK;
- 设置 -XX:MaxPermSize=256M 解决 Eclipse 判断虚拟机版本的 bug;
- 加入参数 -Xverfify:none 禁止字节码验证;
- 虚拟机运行在 client 模式,采用 C1 轻量级编译器;
- 把 -Xms 和 -XX:PermSize 参数设置为 -Xmx 和 -XX:MaxPermSize 一样,这样强制虚拟机启动时把老年代和永久代的容量固定下来,避免运行时自动扩展;
- 增加参数 -XX:DisableExplicitGC 屏蔽掉显式GC触发;
- 采用 ParNew+CMS 的垃圾收集器组合;
- 最终从 Eclipse 启动耗时 15 秒到 7 秒左右, eclipse.ini 配置如下: