Sqoop 源码 :https://github.com/apache/sqoop
Sqoop 用户手册 :http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
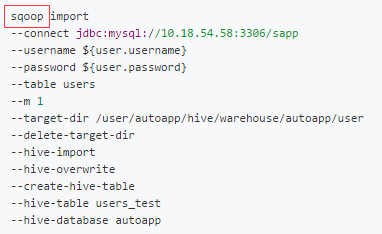
命令示例
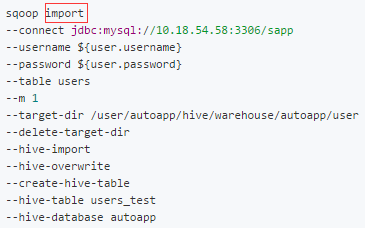
Sqoop 从 MySQL 导入到 Hive 命令示例
sqoop import
--connect jdbc:mysql://10.18.54.58:3306/sapp
--username ${user.username}
--password ${user.password}
--table users
--m 1
--target-dir /user/autoapp/hive/warehouse/autoapp/user
--delete-target-dir
--hive-import
--hive-overwrite
--create-hive-table
--hive-table users_test
--hive-database autoapp
总体流程
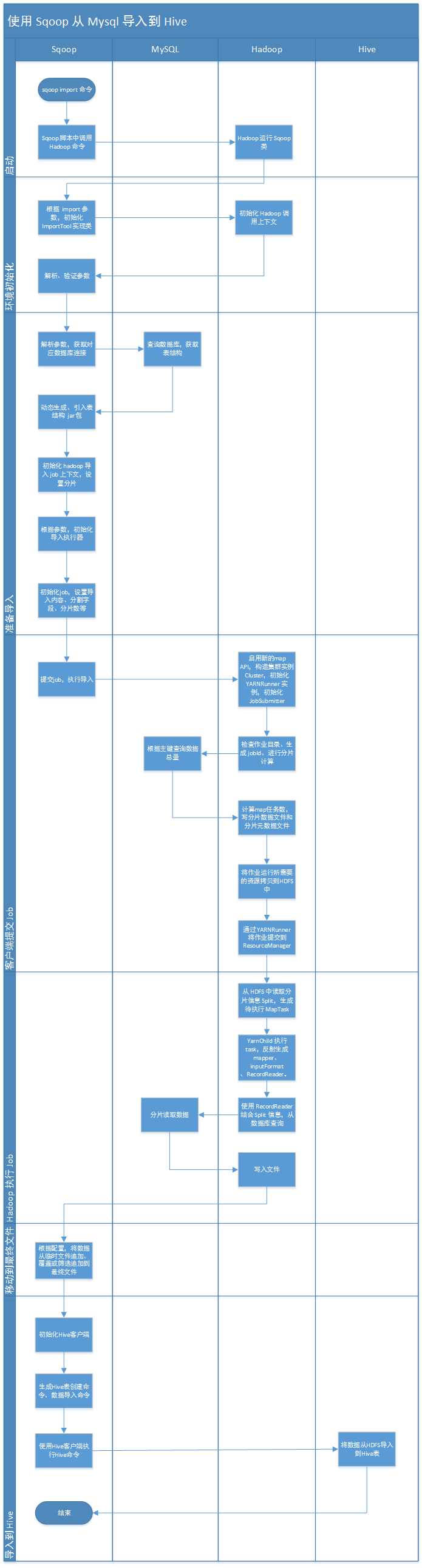
1、执行入口
首先查看sqoop命令中的第一个单词,sqoop,背后的执行过程。
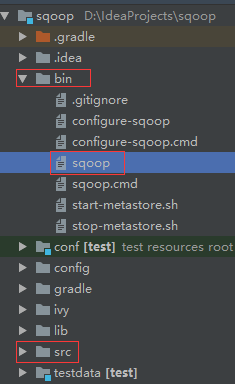
1)目录
主要关注 sqoop 源码的 bin 和 src 目录,bin 目录里是执行脚本,src 目录里是具体执行的 Java 源码。
2)脚本入口
sqoop 安装时已经配置好${HADOOP_COMMON_HOME}等变量,并且运行时需要启动 hadoop。
sqoop 命令执行的是源码中的 bin/sqoop 文件,在 sqoop 文件的中:
- 首先定义了查找路径的
follow函数(太长没截图) - 然后使用
follow函数找到$0sqoop 文件的路径 - 接着
source执行 bin/configure-sqoop 文件中的命令,其中检查了 SQOOP、HADOOP、HBASE、HCAT、HIVE、ACCUMULO、ZOOKEEPER等依赖的环境配置 - 最后使用 hadoop 命令,运行 org.apache.sqoop.Sqoop 类,并将 sqoop 命令后面的
$@所有参数传入。

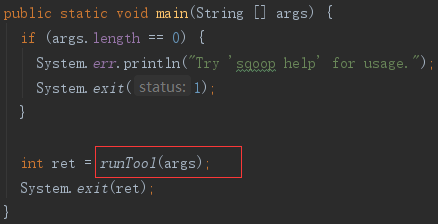
3)Java入口
org.apache.sqoop.Sqoop.java 文件在 src 目录下,其中的入口 main 函数,将参数传入了同类中的 runTool 方法。
2、初始化执行工具
然后解析sqoop命令的第一个参数,import,加载本次命令的实现类。
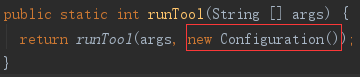
1)默认配置
runTool 方法里,新建了一个默认 Configuration 实例,Configuration 初始化时设置了默认配置,如类加载器等。再将参数和配置,重载到另一个 runTool 方法。
2)加载命令实现类
后面的 runTool 方法中:
- 取第一个参数作为工具名,根据工具名加载工具实现类;
- 根据默认配置加载插件设置项;
- 使用工具实现类和插件设置项初始化一个Sqoop实例;
- 最后执行 runSqoop 方法。
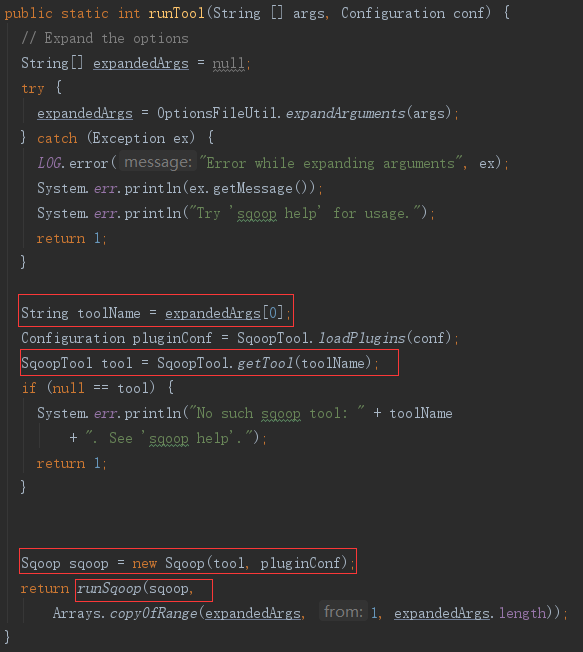
(1)SqoopTool 类
SqoopTool 是一个抽象类,org.apache.sqoop.tool 目录下提供了各种不同命令对 SqoopTool 的扩展类,在SqoopTool 类静态初始化时,类名与命令参数关联在一个类变量TOOLS里。而import参数关联的是ImportTool.class类。
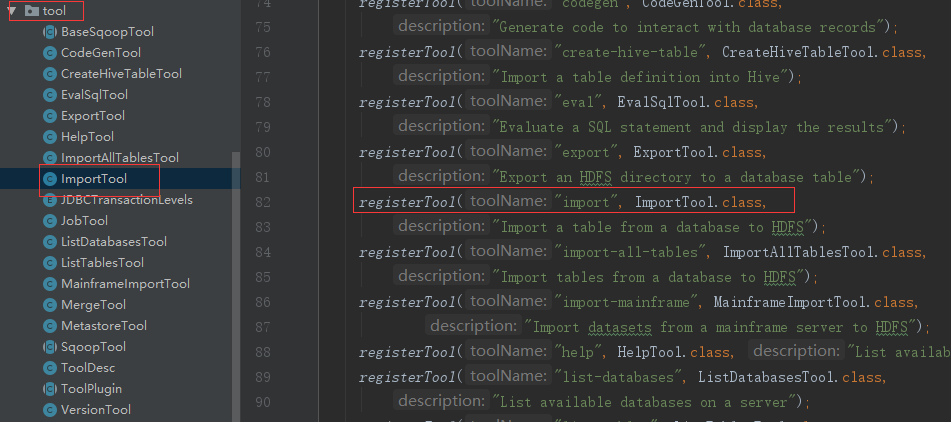
(2)ImportTool 类
getTool 方法根据工具名import,获取了工具类ImportTool.class,并用类反射初始化了一个ImportTool类实例。
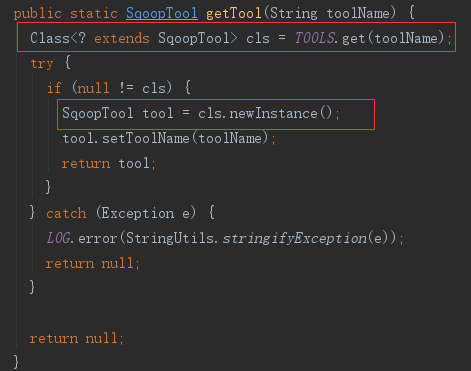
ImportTool初始化时,还实例化了 CodeGenTool 类和 HiveClientFactory 类,后续会用上。
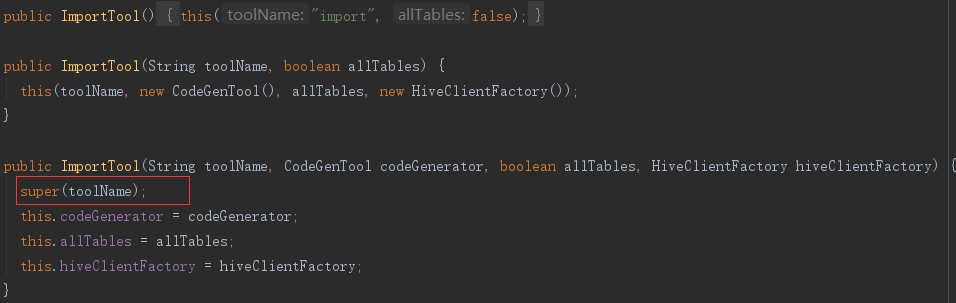
(3)Sqoop 类
Sqoop 类跟 hadoop 相关,扩展了 org.apache.hadoop.conf.Configured 类,并继承了 org.apache.hadoop.util.Tool 类,Sqoop 类初始化时新建了 SqoopOptions 实例,而 SqoopOptions 在初始化时,设置了许多默认参数,诸如hadoopMapRedHome、numMappers之类。
3、初始化执行环境
runSqoop 方法先解析、隐藏子参数,然后调用 ToolRunner.run。
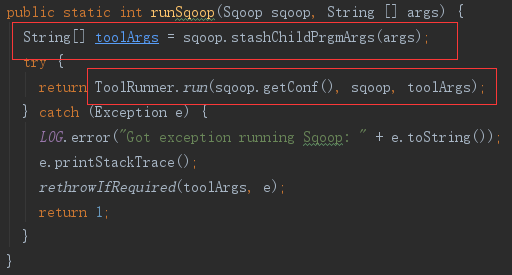
1)隐藏子参数
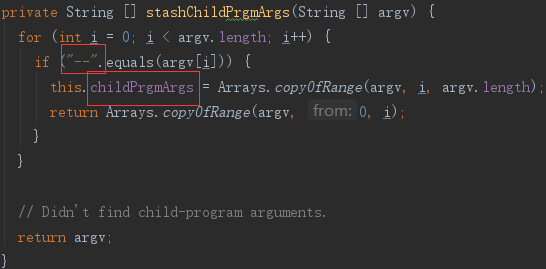
以–开头子参数是供子程序,如 mysqldump,使用的,而 ToolRunner 会剔除这些参数,所以这里先将子参数提取出来,存在 Sqoop.childPrgmArgs 变量中,之后再使用。
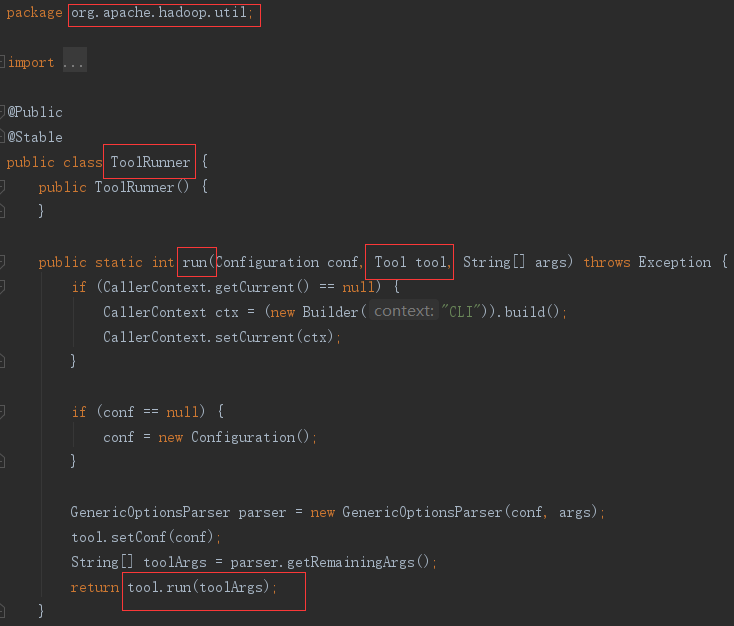
2)初始化 hadoop 调用上下文
ToolRunner是 hadoop 的方法,里面先初始化了调用上下文,然后解析参数,最后调用了 入参 tool 的 run 方法。这里的 tool 是上一步调用传入的 Sqoop 类实例,Sqoop 类是 Tool 类的子类。
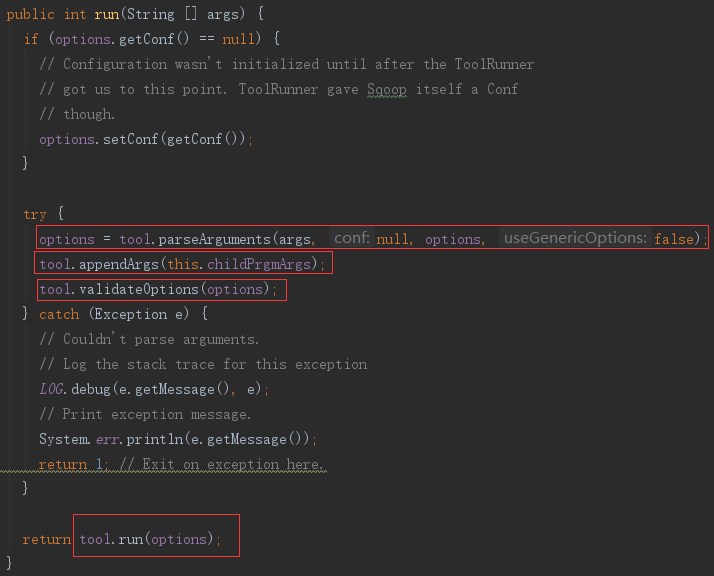
3)准备 ImportTool
Sqoop 类的 run 方法中实例变量,options 是初始化时传入的 SqoopOptions 实例,tool 是初始化时传入的 ImportTool 实例。
- 解析参数,将参数的值,添加到 options 中;
- 取回之前隐藏的子参数
- 验证参数的配置约束、冲突限制
使用解析好的参数,执行ImportTool的 run 方法。
4 执行 Import
ImportTool 的 run 方法,先执行 init 初始化数据库连接Manager,然后执行 importTable 方法——将数据从数据库导入hdfs的具体方法。
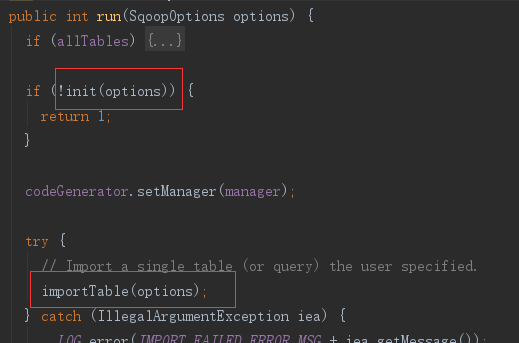
1)init 数据库连接Manager
init 方法中先新建连接工厂 ConnFactory,再从工厂中获取管理器。
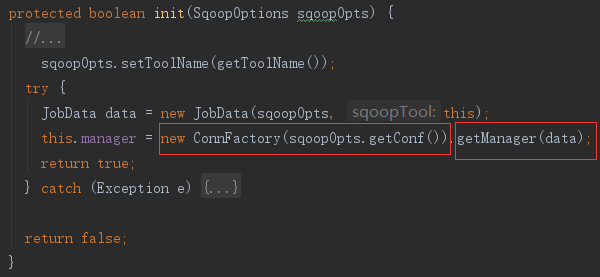
(1)ConnFactory 初始化
连接工厂 ConnFactory 初始化时加载了一系列管理工厂 ManagerFactory,先从配置文件中读取配置的工厂(若有),接着再添加代码中写死的默认 ManagerFactory。
(2)getManager 获取 ConnManager
由于数据库驱动可以使用--driver、--connection-manager参数指定,所以先从参数里读取这两个特定参数,若有值,则直接生产对应的 ConnManager,否则遍历所有 ManagerFactory,从其他参数中找到最匹配的 ConnManager。
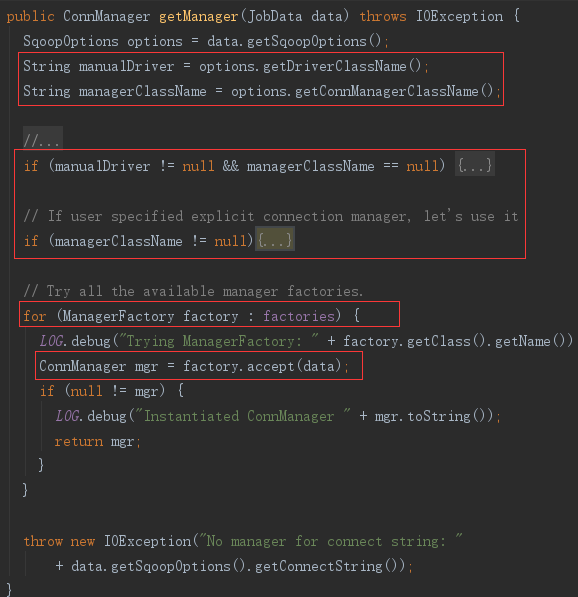
比如本次导入的命令,没有指定 driver,会再默认的 DefaultManagerFactory 中匹配到 ConnManager 的扩展 —— MySQLManager,过程如下:
在遍历到 DefaultManagerFactory 时,执行了DefaultManagerFactory 的 accept 方法。accept 中依次比较各种定义好的,sqoop支持的数据库类型枚举。使用枚举的 isTheManagerTypeOf 方法判断参数是否符合这个数据库类型。
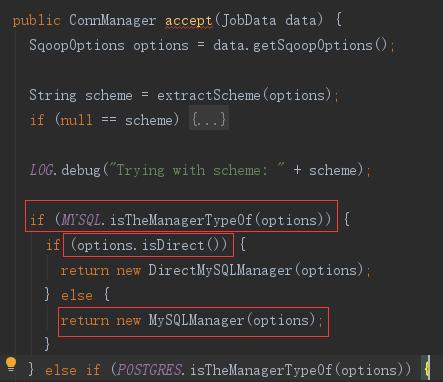

extractScheme(options) 从参数中获取--connect参数的值,截取参数值//前面的部分
--connect jdbc:mysql://10.18.54.58:3306/sapp
//截取后的值
jdbc:mysql:
再用 getSchemePrefix() 获取枚举的前缀,截取部分与前缀比较,符合 MYSQL 的前缀。

由于本次参数没有配置--direct设置 direct 模式,所以返回的连接管理器是新建的 MySQLManager 实例。
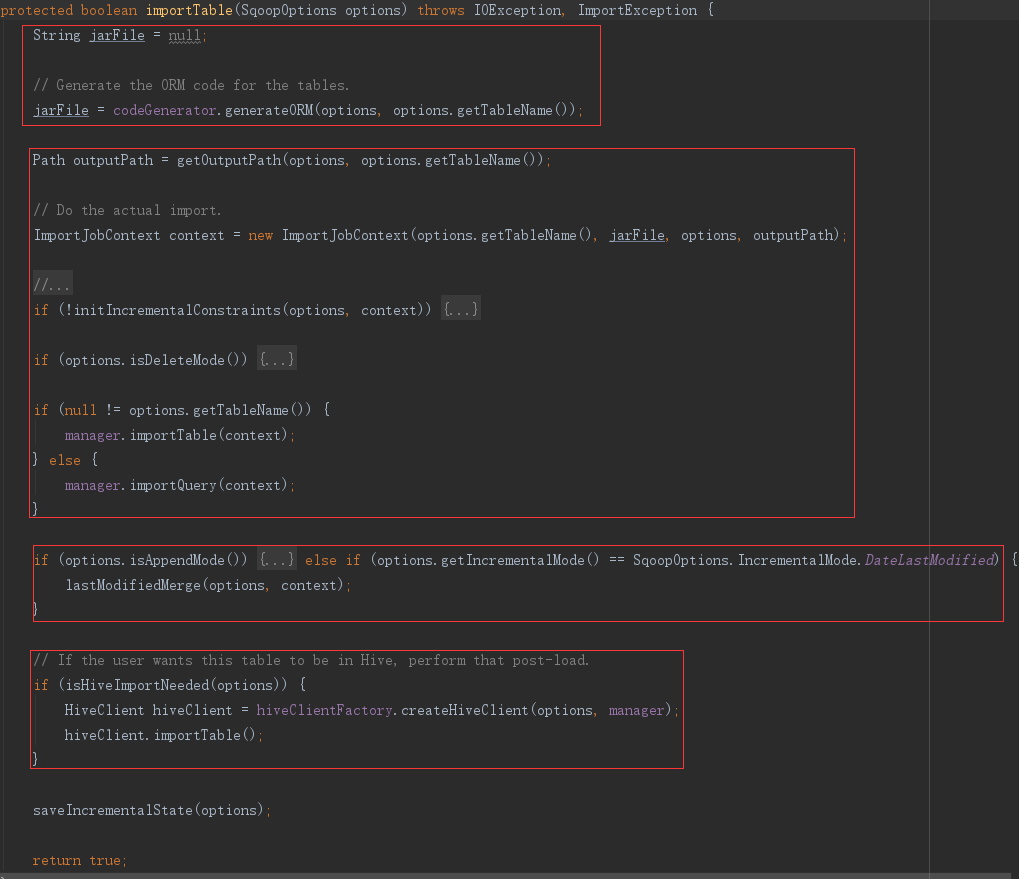
2)importTable
在 importTable 方法里,即将正在开始导入数据。分四步:
- 生成表代码
- 导入数据
- (可选)追加模式
- (可选)导入hive
importTable 内容比较多,下面分开解析。
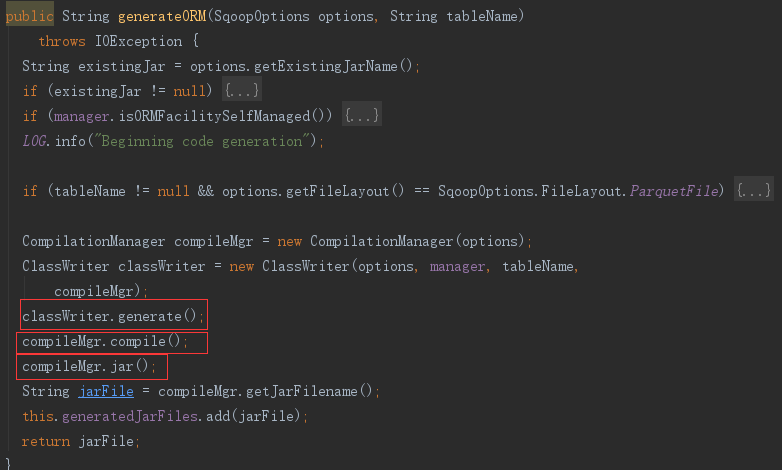
5 生成表代码
主要分三步
- 生成:classWriter.generate();
- 编译:compileMgr.compile();
- jar包:compileMgr.jar();
1)生成表文件
generate()方法中根据表结构生成了表对象的java文件
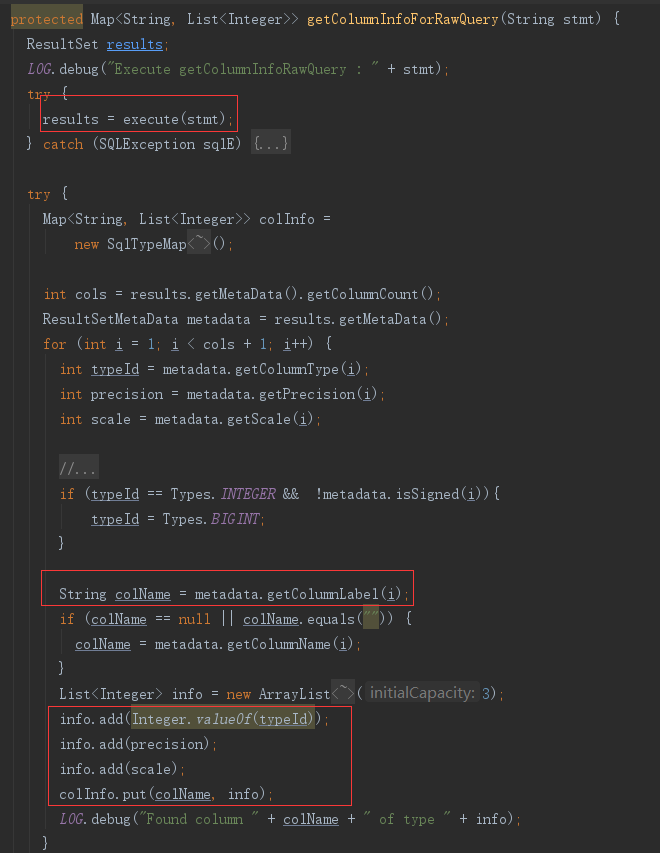
(1)读取表结构

生成查询语句,可以通过参数配置,若没有配置则使用默认语句。

执行语句,并解析表结构,获取表字段,及整数格式的字段类型
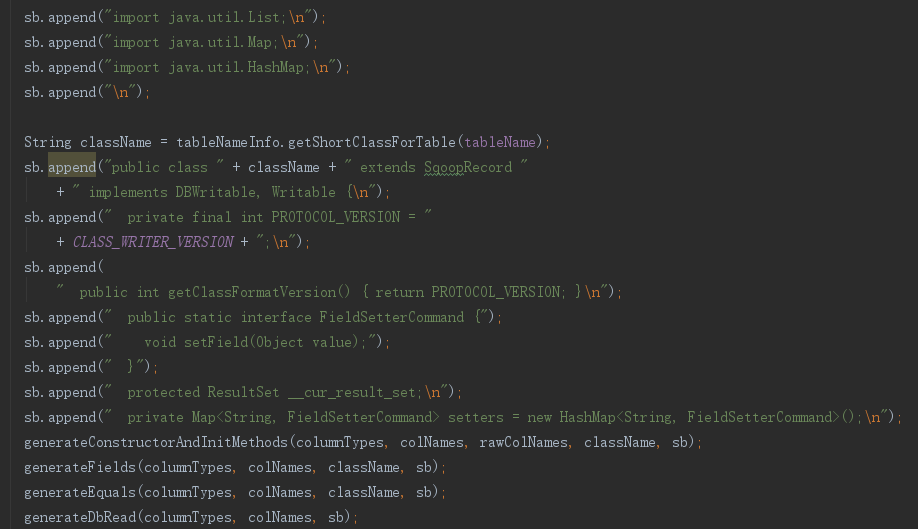
(2)生成表文件
整理表字段
字段名加_前缀,将整数字段类型转为对应java类型
生成java类内容
使用数据库表字段调用 generateClassForColumns 方法,生成表对象的java文件内容
生成java文件容
生成文件名,将文件内容写入文件中
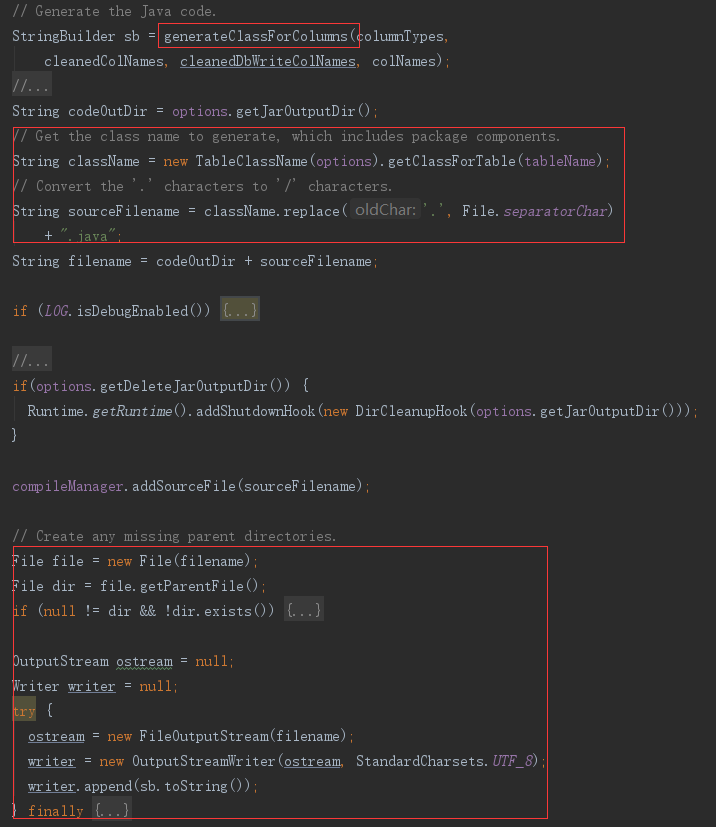
2)编译表文件
compileMgr.compile() 中
配置生成参数(hadoop和sqoop的jar路径)、读取刚刚生成的.java文件,使用默认的java编译器,在默认输出路径(可配置)生成.CLASS文件
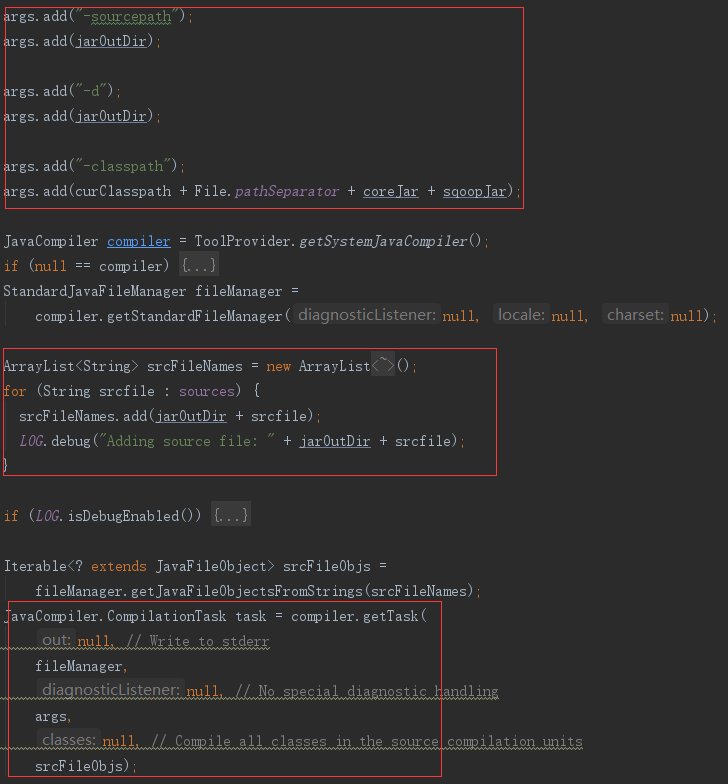
3)生成 jar 包
compileMgr.jar();分别获取要写入的.class文件名,和 jar 包文件名,然后使用 addClassFilesFromDir 方法将的.class文件添加到 jar 包写入流 jstream 中,最后写入 jar 文件。
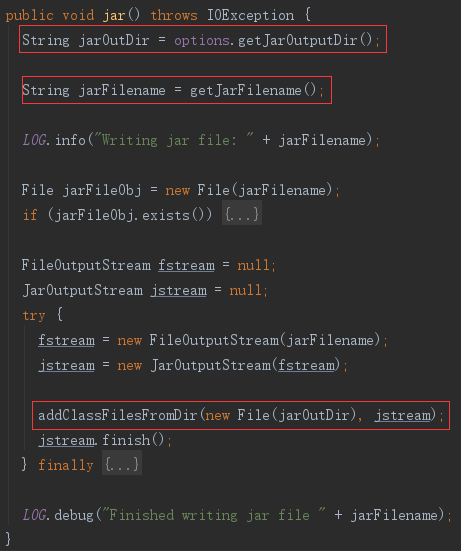
6 导入数据
导入数据时先使用上面生成的jar包和参数初始化一下数据,然后使用 manager.importTable 方法真正导入。这里的 manager 是之前匹配到的 MySQLManager 实例,MySQLManager 的 importTable 语句,实际上执行的是它的超类 SqlManager,的 importTable。
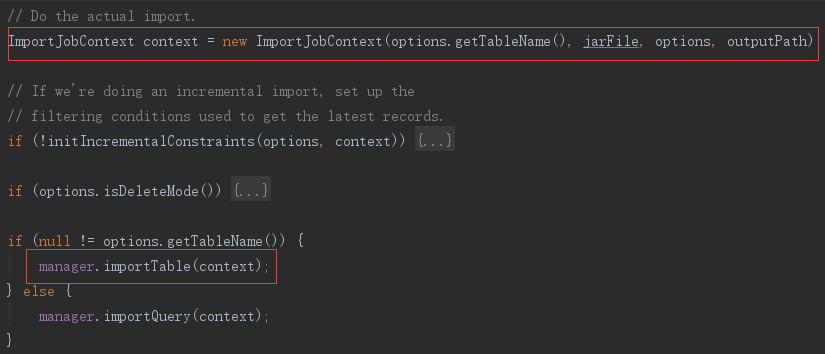
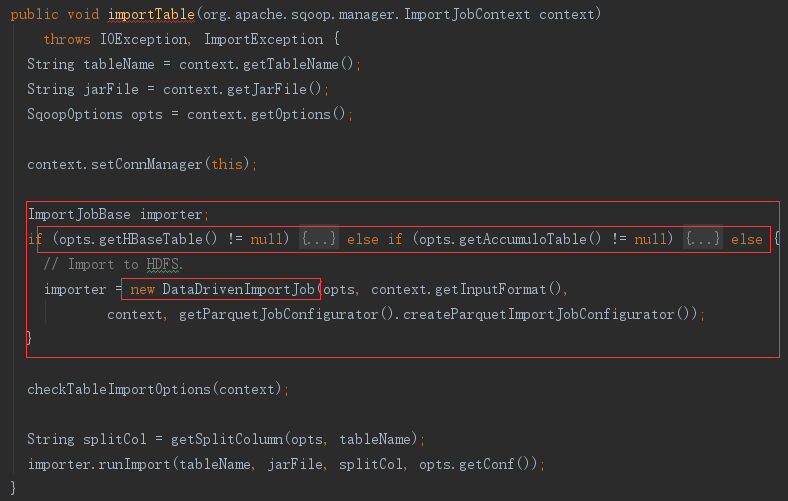
1)选择 ImportJobBase
首先根据参数选择ImportJobBase的实现类,由于我们的参数中没有配置hbase和accumulo的参数,所以会选择 DataDrivenImportJob导入HDFS。然后执行 importer.runImport 方法
2)runImport
(1)加载 jar
获取Class名
首先根据表名获取待加载的类名,如果有参数指定,则使用参数指定的类名,没有就根据表名构造
加载Class
在 loadJars 方法中,使用 ClassLoader 从 jar 包中加载表的 ORM Class
loadJars(conf, ormJarFile, tableClassName);
(2)提交 Job
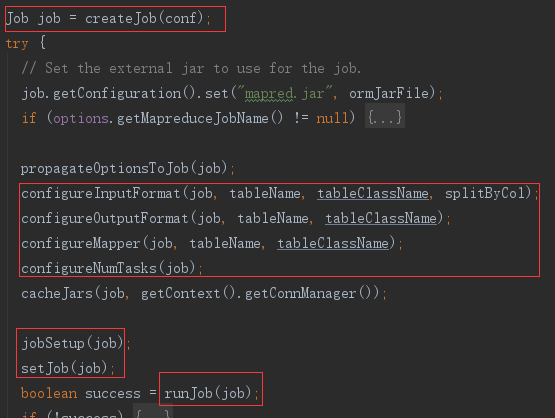
初始化
首先根据配置项初始化一个 Job
设置参数
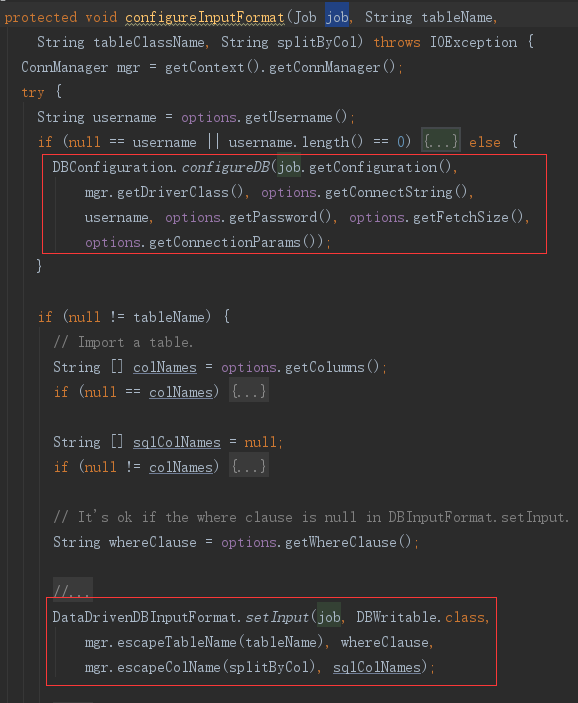
然后使用 DataDrivenImportJob 实现的 configure* 方法配置 Job 执行属性。例如 configureInputFormat 配置 job 的输入参数,数据库链接、表名、列名
执行Job
最后正式运行 MapReduce job。 runJob 方法里调用了 doSubmitJob 方法,doSubmitJob 方法里最终运行的是 job.waitForCompletion(true),提交到 hadoop,并阻塞等待执行结果。
自此数据就从数据库导入到了hdfs中的临时目录。
如果给 sqoop 配置 listener,并且参数里有--hive-import,这里还会发一条 import 消息。
7 移动到最终目录
数据导入到临时文件之后之后,根据配置,将数据从临时文件追加、覆盖或筛选追加到最终文件
默认是追加
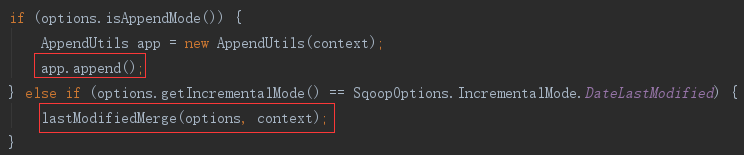
(1)追加导入
–-append参数,会操作hdfs文件,将导入的数据移动、追加到目标文件中。
(2)增量导入
–-incremental参数,会生成新的 Job,数据源是刚刚导入的临时目录中的数据,提交 Job,将增量条件过滤后的数据导入到目标文件中。
8 (可选)导入hive
若配置了--hive-import参数,还需要将数据从 hdfs 导入到 hive 中去。
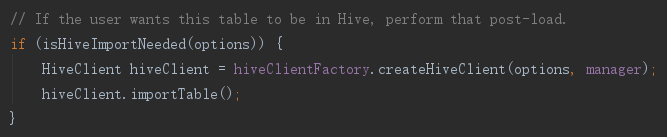
1)生成客户端
首先创建了一个 Hive 客户端,没有特别配置都会生成 HiveServer2Client,然后执行客户端的 importTable 方法。
2)importTable
importTable 方法中就是生成两条 hive 语句,然后通过客户端执行。
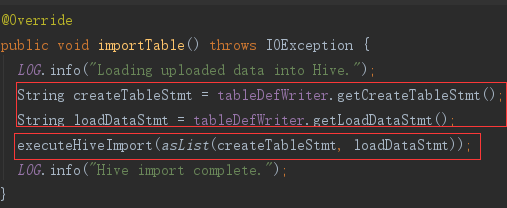
两条语句,一条建表、一条导入,都是根据前面获得的表结构、文件路径等参数,拼接而成。
最后使用客户端建立链接,执行导入操作。
9 附加:Hadoop 中执行 Map 的实现
Sqoop 使用导入参数新建了一个 Job,将具体导入过程提交给 Hadoop 执行,但是 Hadoop MapReduce 过程中执行的分配与数据获取操作的方法实现,是在 Sqoop 中定义好,并配置在 Job中的。
1)分割Map:DataDrivenDBInputFormat
Sqoop 设置在 Job 中供分片中使用的 InputFormat 实现, 是 DataDrivenDBInputFormat 类。
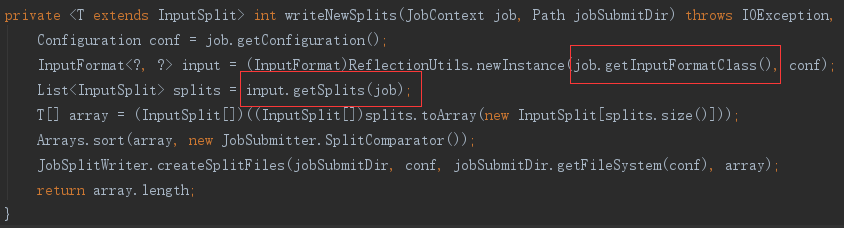
DataDrivenDBInputFormat 的 getSplits 方法,先使用 getBoundingValsQuery 查出主键的范围
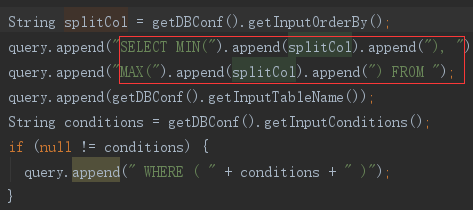
再根据主键类型使用不同分割器,如这里 Long 型主键使用的是 IntegerSplitter。IntegerSplitter 来对主键范围,结合 map 数,计算出分割点。最后得到装有分割信息的 InputSplit 实现数组。

这些分割信息最后都作为分割文件写入HDFS了。
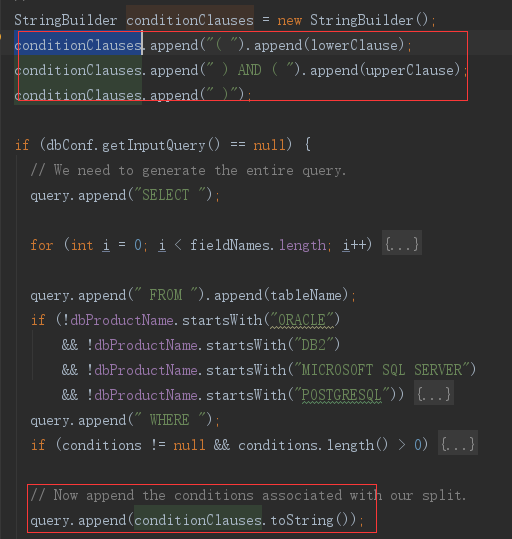
2)读取数据:DataDrivenDBRecordReader
Hadoop 从 HDFS 读取分配信息时,需要使用 RecordReader 来读取 InputSplit 中的数据,而 DataDrivenDBInputFormat 提供的 createDBRecordReader 方法,返回的是 Sqoop 中实现的 DataDrivenDBRecordReader。
DataDrivenDBRecordReader 初始化化时,除了分片信息之外,还从 Job 的参数配置中读取了数据库连接信息,查询表名,查询字段列表,查询条件,查询结果 ORM 类等所有必须信息。

从数据库读取具体信息时,先使用 DataDrivenDBRecordReader 的 getSelectQuery 方法获取查询语句,而 DataDrivenDBRecordReader 初始化时就已经包含了查询必要信息。