对比
- BIO (Blocking I/O)
- 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。
- 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。
- 适用于连接数比较小的情况,编程模型简单,不用过多考虑系统的过载、限流等问题。
- I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。
- NIO (Non-blocking I/O)
- 同步非阻塞的 I/O 模型,Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。
- 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
- NIO 提供了与传统 BIO 模型中的
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。 - 虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。
- AIO (Asynchronous I/O)
- 异步非阻塞的 I/O 模型。Java 7 中引入,AIO 也就是 NIO 2。
- AIO 的异步是基于事件和回调机制实现的
1 核心概念
1.1 通道
通道 Channel 是对原 I/O 包中的流的模拟,通道是双向的。读写数据通过 Channel,再到通道。可以访问诸如内存映射、文件加锁机制以及文件间快速数据传递等操作系统特性。
获取通道
FileChannel channel = FileChannel.open(path,options);
1.2 缓冲区
缓冲区 Buffer 是一个容器对象,包含一些要写入或者刚读出的数据。通道读写的数据首先放到缓冲区。
缓冲区实质上是一个数组。通常是字节数组,也可使用其他数组。缓冲区不仅仅是一个数组,还提供了对数据的结构化访问,且还可以跟踪系统的读/写进程。
获取缓冲区
- 直接获取
ByteBuffer buffer = ByteBuffer.allocate(1024);
- 数组转换
byte array[] = new byte[1024];
ByteBuffer buffer = ByteBuffer.wrap( array );
- 从通道获取
调用FileChannel类的map方法从这个通道中获得一个ByteBuffer。可以指定想要映射的文件区域与映射模式,支持的模式有三种:- FileChannel.MapMode.READ_ONLY:
缓冲区只读 - FileChannel.MapMode.READ_WRTE:
缓冲区可写,修改都会在某个时刻写回到文件中 - FileChannel.MapMode.PRIVATE:
缓冲区可写,修改个缓冲区私有,不会传播到文件中。
- FileChannel.MapMode.READ_ONLY:
ByteBuffer buffer = channel.map(FileChannel.MapMode.PRIVATE, 0, 1024);
1.3 读写操作
每种基本 Java 类型都有一种缓冲区类型,以 ByteBuffer 类为例,可以在其底层字节数组上进行 get、set 操作读写数据。
1)读操作
// 获取通道
FileInputStream fin = new FileInputStream( file );
FileChannel fc = fin.getChannel();
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
// 将数据从通道读到缓冲区中
channel.read(buffer);
顺序访问
byte[] b = buffer.array();
//or
while (buffer.hasRemaining()){
byte b = buffer.get();
}
随机访问
for ( int i=0;i < buffer.limit(); i++){
byte b = buffer.get(i);
}
访问顺序
Java 对二进制数据使用高位在前的排序机制,但如需以低位在前处理:
buffer.order(ByteOrder.LITTLE_ENDIAN);
查询缓冲区内当前的字节顺序:
ByteOrder b = buffer.order();
2)写操作
// 获取通道
FileOutputStream fout = new FileOutputStream(file);
FileChannel channel = fout.getChannel();
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
// 写入数据
for (int i = 0; i < message.length; ++i) {
buffer.put( message[i] );
}
// 反转缓冲区
buffer.flip();
// 写入缓冲区
channel.write( buffer );
在恰当的时候,以及当通道关闭时,会将这些修改写回到文件中。
反转
buffer.flip();为读入后的输出做准备
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
- 将limit设置为当前position。
- 将position设置为0。
3)读写结合
拷贝
public static void fileCopyNIO(String source, String target) throws IOException {
try (FileInputStream in = new FileInputStream(source)) {
try (FileOutputStream out = new FileOutputStream(target)) {
FileChannel inChannel = in.getChannel();
FileChannel outChannel = out.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(4096);
while (inChannel.read(buffer) != -1) {
buffer.flip();
outChannel.write(buffer);
buffer.clear();
}
}
}
}
重设缓冲区
buffer.clear();初始化缓冲区
public final Buffer clear() {
osition = 0;
limit = capacity;
mark = -1;
return this;
}
- 将 limit 设置为与 capacity 相同。
- 设置 position 为 0。
2 缓冲区数据结构
缓冲区是由具有相同类型的数值构成的数组,有复杂的内部统计机制,会跟踪已经读了多少数据以及还有多少空间可以容纳更多的数据。
缓冲区有两个重要组件:状态变量和访问方法。实现机制看起来复杂,但大都封装好了,只需像平时使用字节数组和索引变量一样进行操作即可。
2.1 状态变量
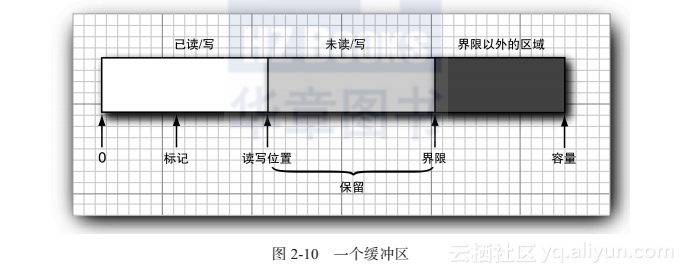
如图,每个缓冲区都具有:
- capacity
容量,永远不变 - position
读写位置,下一个值在此读写。初始0 - limit
界限,超过它进行读写没有意义 - mark
可选的标记,用于重复一个读入或写出操作。默认-1
这些值满足: 0<= mark <= position <= limit <= capacity
每一个基本类型的缓冲区底层实际上就是一个该类型的数组。如在 ByteBuffer 中,有:
final byte[] hb;
2.2 访问方法
使用缓冲区的主要目的是执行“写,然后读入”循环。
- 假设有一个缓冲区,初始位置为 0,界限等于容量。
- 不断地调用 put 将值添加到这个缓冲区中,当耗尽所有的数据或者写出的数据量达到容量大小时,就该切换到读入操作了。
- 调用 flip 方法将界限设置到当前位置,并把位置复位到 0。
- 在 remaining 方法返回正数时(它返回的值是“界限-位置”),不断地调用 get。
- 在缓冲区的值都读入之后,调用 clear 使缓冲区为下一次写循环做好准备。clear 方法将位置复位到 0,并将界限复位到容量。
如果想重读缓冲区,可以使用 rewined 或 mark/reset 方法。
要获取缓冲区,可以调用诸如 ByteBuffer.allocate 或 ByteBuffer.wrap 这样的静态方法。
然后,可以用来自某个通道的数据填充缓冲区,或者将缓冲区的内容写出通道中。
ByteBuffer buffer = ByteBuffer.allocate(RECORD_SIZE);
channel.read(buffer);
channel.position(newpos);
buffer.flip();
channel.write(buffer);
3 文件加锁机制
文件锁可以解决并发修改同一个文件的问题,它可以控制对文件或文件中某个范围的字节的访问。
3.1 锁定整个文件
1)lock
获得独占锁,阻塞直至获得锁。
FileChannel = FileChannel.open(path);
FileLock lock = channel.lock();
2)tryLock
获得独占锁,在无法获得的情况下返回 null。
FileLock lock = channel.rtyLock();
3.2 锁定部分文件
在文件区域上获得锁,阻塞直至获得锁。
FileLock lock (long start,long size,boolean shared)
在文件区域上获得锁,无法获得锁时返回 null。
FileLock tryLock(long start,long size,boolean shared)
- shared 为 false
如果 shared 标志为 false,则锁定文件的目的是读写 - shared 为 true
则这是一个共享锁,它允许多个进程从文件中读入,并阻止任何进程获得独占的锁。并非所有的操作系统都支持共享锁,因此你可能会在请求共享锁的时候得到的是独占的锁。
1)锁类型
调用 FileLock 类的 isShared 方法可以查询所持有的锁的类型。
2)锁区间
如果锁定了文件的尾部,而这个文件的长度随后增长了超过锁定的部分,那么增长出来的额外区域是未锁定的,要想锁定所有字节,可以使用Long.MAX_VALUE来表示尺寸。
3.3 释放锁
try(FileLock lock = channel.lock()){
access the locked file or segment
}
3.4 注意
文件加锁机制时依赖操作系统的
- 在某些系统中,文件加锁仅仅是建议性的,如果是一个应用未能得到锁,它仍旧可以向被另一个应用并发锁定的文件执行写操作。
- 在某些系统中,不能在锁定一个文件的同时将其映射到内存中。
文件是由整个 Java 虚拟机持有的。如果有两个程序是由同一个虚拟机启动的,那么它们不可能每一个都获得一个在同一个文件上的锁。当调用 lock 和 tryLock 方法时,如果虚拟机已经在同一个文件上持有了另一个重叠的锁,那么这两个方法将抛出 OverlappingFileLockException。 - 在一些系统中,关闭一个通道会释放由 Java 虚拟机持有的底层文件上的所有锁。因此,在同一个锁定文件山海关应避免使用多个通道。
- 在网络文件系统上锁定文件时高度依赖与系统的,因此应尽量避免。