binlog 异步么
acid
B+树、索引结构、索引的分类、乐观锁、悲观锁、共享锁、排它锁、MVCC、GAP、ACID特性、隔离级别、事务原理、造成数据库死锁的原因,如何避免数据库死锁、如何使用explain、什么情况下会导致索引失效、如何进行数据库优化、建立索引需要注意什么
01 关系数据库
三范式
- 1NF:属性不可分。
- 2NF:表必须有一个主键 + 非主键必须完全依赖于主键。
- 3NF:非主键列必须直接依赖于主键,不能存在传递依赖。
02 锁
1 锁粒度
- 表锁(开销最小的锁策略)
- 行锁(最大程度地支持并发处理,在存储引擎层实现)
2 锁类型
- 读写锁
- 读锁(共享锁,不阻塞,读锁上还可再加读锁)
- 写锁(排它锁,阻塞,不能再加锁)
- 意向锁
- 表锁,只是表示想要对表加锁,不是真正加锁
3 间隙锁(Next-Key Locks)
- Record Locks
- 锁定一个记录上的索引,而不是记录本身。
- Gap Locks
- 锁定索引之间的间隙,但是不包含索引本身。
- Next-Key Locks
- 它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。
03 事务
MySQL 默认采用自动提交模式。如果不是显式地开始一个事务,那么每个查询都会被当做一个事务自动提交。
1 ACID
原子性(Atomicity,回滚日志 undo log)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability,重做日志 redo log)
2 隔离级别
未提交读(脏读)、提交读(不可重复性读)、可重复读(默认级别,MVCC+间隙锁 解决幻读)、可串行化
04 多版本并发控制
MVCC 是行级锁的一个变种,尽可能避免加锁,用“事务版本号”比较“行版本号”和“行删除标识”,进行校验
05 存储引擎
- InnoDB:MySQL 的默认事务型存储引擎,被设计用来处理大量的短期事务。
- MyISAM:MySQL 5.1及之前的默认存储引擎,不支持事务和行级锁,空间占用少,适合读。
06 索引
索引(Index)是帮助 MySQL 高效获取数据的数据结构。在存储引擎中实现。
- B树(B-tree)
- 平衡多叉树,适合查找范围数据。
- key为记录的键值;data为数据记录除key外的数据。
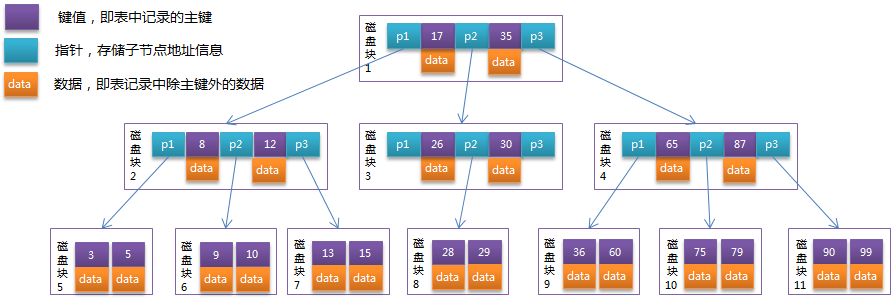
- B+Tree
- 基于“B Tree”,增加“叶子节点顺序访问指针”(区间查询)
- 内节点不存储data;叶子节点不存储指针。

- 哈希索引
- 能以 O(1) 时间进行查找,但是失去了有序性,无法用于排序与分组、部分查找和范围查找。
- InnoDB “自适应哈希索引”:当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引
07 水平垂直拆分
- 水平拆分:将一张表中的记录拆分到多个结构相同的表中。减缓单个数据库的压力。
- 垂直拆分:将一张表的字段拆分为主表以及扩展表,使用频次较高的字段在一张表,其余的在一张表。
- 分布式 ID 生成器:Snowflake 雪花算法
- 拆分策略:哈希取模、范围划分、映射表
08 主从复制
- 复制过程:主库将数据更改按事务提交顺序写道 Bin Log 中,从库(默认)异步将主库的 Bin Log 数据复制到自己的 Replay Log中,然后在从库中重放 Replay Log 中的 SQL
- 复制原理:MySQL 默认使用“基于语句”的复制,在发现语句无法正确被复制时,会动态切换到“基于行”的复制。
- 强一致性:Loss-Less 半同步复制,事务在“Bin Log 落日志”+“任意从库 Replay Log 落日志”后,才返回提交成功
- 读写分离:主库(写操作+高实时性读操作),从库(读操作)。
09 其它
1 SQL注入
- 举例:数字注入(id=-1 OR 1 =1)、字符串注入(注释掉)
- 预防:严格检查输入变量的类型和格式、过滤和转义特殊字符、利用mysql的预编译机制
2 删除重复记录
NOT IN
DELETE FROM visitor_province_yn
WHERE id NOT IN(
SELECT id
FROM(
SELECT MIN(vpy.id) AS id
FROM visitor_province_yn AS vpy
GROUP BY vpy.visitor, vpy.province, vpy.yn
) AS tmp
);