1 HIVE 简介
- 是基于 Hadoop 的一个数据仓库工具
- 可以将结构化的数据映射为一张数据库表
- 并提供 HQL(Hive SQL)查询功能
- 底层数据是存储在 HDFS 上
- Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
- 使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
2 HIVE架构
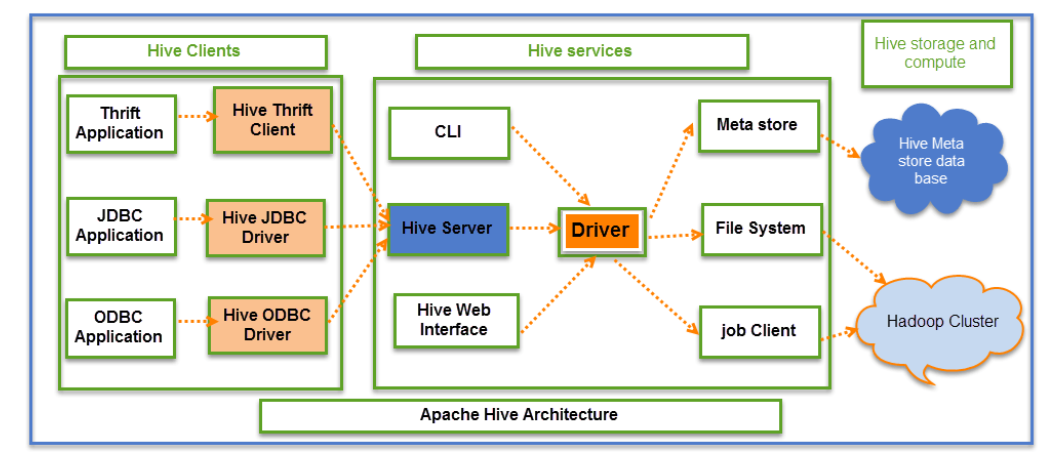
1)Hive Clients
用户操作Hive的接口主要有三个:CLI,Client 和 Web UI, 其中最常用的是CLI。
CLI启动的时候,会同时启动一个Hive副本, Client是Hive的客户端,用户连接至Hive Server。
在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。
而客户端则又可以分为三种Thrift Client、JDBC Client、ODBC Client。
2)Hive Services
客户端与Hive的交互通过Hive Service来完成,客户端希望执行的任何Hive查询操作必须通过Hive Service来进行通信,Hive Service中的驱动程序处理来自不同应用程序的请求,以便mete store和filed system进一步处理。
3)Hive Storage and Computing
Hive服务如Meta store,File system和Job Client依次与Hive Store交互执行以下操作:
- 在Hive中创建的表的元数据信息存储在Meta storage database。
- 查询结果和加载在表中的数据存储在HDFS上的Hadoop集群上。
3 Hive的缺优点
优点
- 可扩展性:Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务
- 延展性:Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
- 容错性:可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点
- Hive 不支持记录级别的增删改操作
- Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能用在交互查询系统中。
- Hive 不支持事务(因为没有增删改,所以主要用来做 OLAP(联机分析处理),而不是 OLTP(联机事务处理),这就是数据处理的两大级别)。