一、逻辑架构
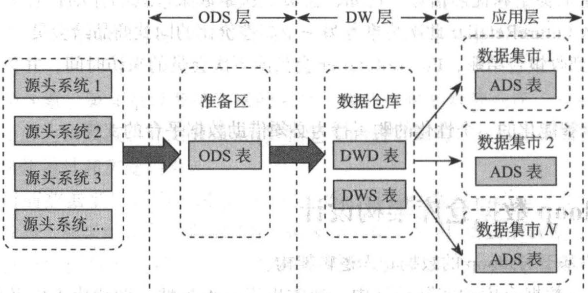
1、ODS 层
ODS ( Operation Data Store)层通常也被称为准备区,原样存储来源系统的数据表,是后续数据仓库层加工数据的来源。同时 ODS 层也存储着历史的增量或者全量数据。
2、DW 层
数据仓库层(DW 层)的数据是 ODS 层数据经过 ETL 清洗、转换、加载生成的。数据平台的下游用户将会直接使用 DW 层数据,而 ODS 层数据原则上不允许下游用户直接接触和访问。
DW 层数据保存最细粒度的事实表和维度表(DWD,即 DW 层的明细层),并基于它们生成一层汇总数据(DWS,即 DW 层的汇总层)。
3、应用层
在 DW 层的基础上,各个业务方或者部门可以建立自己的数据集市(Data Mart),此层一般称为应用层。应用层的数据来源于 DW 层,原则上不允许应用层直接访问 ODS 层。
相比 DW 层,应用层只包含部门或者业务方自己关心的明细层和汇总层数据。应用层数据表等一般由下游用户自己维护和开发,数据平台团队提供咨询和支持,但是拥有者应该为下游数据用户。
二、命名规范
1、表命名规范
表命名规范是为了让数据所有相关方对于表包含的信息有一个共同的认知。数据平台建设者应该首先规定数据仓库分层、 业务领域、常见维度和时间跨度等的英文缩写,并据此给出表的命名规范。
dws_sls_item_m
- 数据仓库分层:可能取值为 ODS (ODS 层表)、DWD(DW 明细层表)、DWS ( DW 汇总层表)、 ADS(应用层表)等。
- 业务领域:可能取值为 sls(销售)、inv(库存)等。
- 常见维度:用户自定义的业务、项目和产品标签。比如买家为 byr,卖家为 slr。
- 时间跨度 :时间标签,比如 d 为天、m 为月、y 为年、di 为增量表、df 为全量表等 。
2、字段命名规范
字段命名规范应该是有意义而且易于理解的,最好是能够表达字段含义的英文字母。
比如,数量型的字段一般以 cnt (count)结尾,数值型的宇段以 amt (amout)结尾,标签性的字段应该以 is 打头。实际项目中,数据平台方可以提供常用的英文缩写、业务缩写等来规范用户的字段命名。
三、维度建模
1、划分业务主题
例如将商店业务主题划分为销售域、库存域、客户服务域、采购域等。
2、定义粒度
对于上述每个主题域,比如销售,需要选择最细粒度的数据,很容易确定销售域的最 细粒度事实为购物小票的子项、库存域的最细粒度为商品 SKU 的库存、 客户服务热线的最 细粒度事实为一次电话呼叫、采购域的最细粒度为某个商品 SKU 的采购申请等。
3、确定维度
确定粒度之后,相关的维度也已基本确定,但是根据 Hadoop 反规范和扁平化的设计思想,还需要确定哪些字段需要反规范化和扁平化到相关维度表中。
4、确定事实
最后一步就是确定需要的事实表,而且应该明确需要哪种类型的事实表,是事务事实表,还是周期快照事实表以及累计快照事实表?如同维度表的反规范化和扁平化设计一样,也要将使用频率高的维度字段反规划化和扁平化到事实表中。
四、数据平台新架构一一数据湖
作为新的大数据架构,数据湖采集和存储一切数据,既包含结构化的数据也包含非结构化(如语音、视频等)和半结构化的数据(如 JSON 和 XML 等),既包含原始数据又包含经过处理的、集成的数据。
数据湖鼓励分析师和数据科学家对原始数据在分析沙箱中进行自由的探索、研究和实验,对于精炼的、有价值的数据,和数据开发、管理团队一起将其转换为更易操作和使用的数据,并供下游分析或者业务人员使用。
数据湖和数据仓库比较
| 对比方面 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 结构化、处理过的数据 | 结构化/半结构化/非结构化/原始数据 |
| 处理模式 | schema-on-wnte | schema-on-read |
| 存储 | 大规模存储昂贵 | 专为低成本存储设计 |
| AGILITY | 灵活性差,固定配置 | 高度灵活,按需配置和重配置 |
| 安全 | 成熟 | 趋于成熟 |
| 业务专家 | 用户 | 数据科学家等 |