1 整体框架
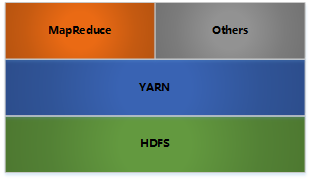
- HDFS: 分布式文件存储
- YARN: 分布式资源管理,允许任何一个分布式程序(不仅仅是 MapReduce)基于 Hadoop 集群的数据运行
- MapReduce: 批处理。分布式计算
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
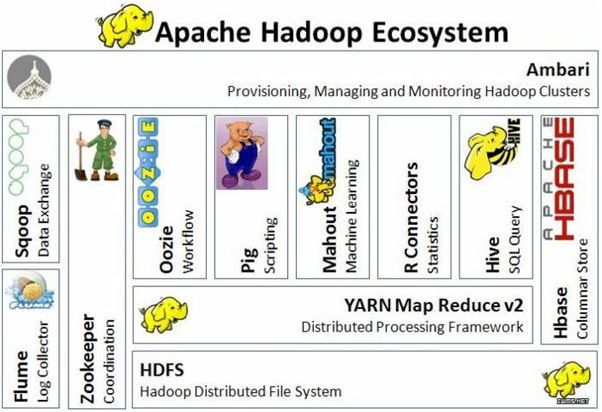
生态系统
数据格式
- Avro:序列化数据
- Parquet
数据摄取
- Flume:日志收集
- Sqoop
数据处理
- Pig:数据分析平台,抽象 MapReduce 脚本
- Hive:交互式SQL。将sql语句转换为MapReduce任务
- Crunch
- Spark:迭代处理。MapReduce 的优化,允许在内存中保存中间结果集
存储
- HBase:分布式列式数据库
协作
- ZooKeeper:协调系统
其他
- Ambari:创建、管理、监视 Hadoop 的集群
- Mahout:机器学习框架
- Storm:流处理。在无边界数据流上运行实时、分布式的运算
- Solr:搜索。