参考: HBase 深入浅出
1 HBase 简介
- HBase(Hadoop Database)是Bigtable的开源实现
- 稀疏的,面向列
- 基于HDFS,高可靠,可伸缩
- 利用Zookeeper进行协同服务
- 适合大数据随机和实时读写
2 HBASE架构
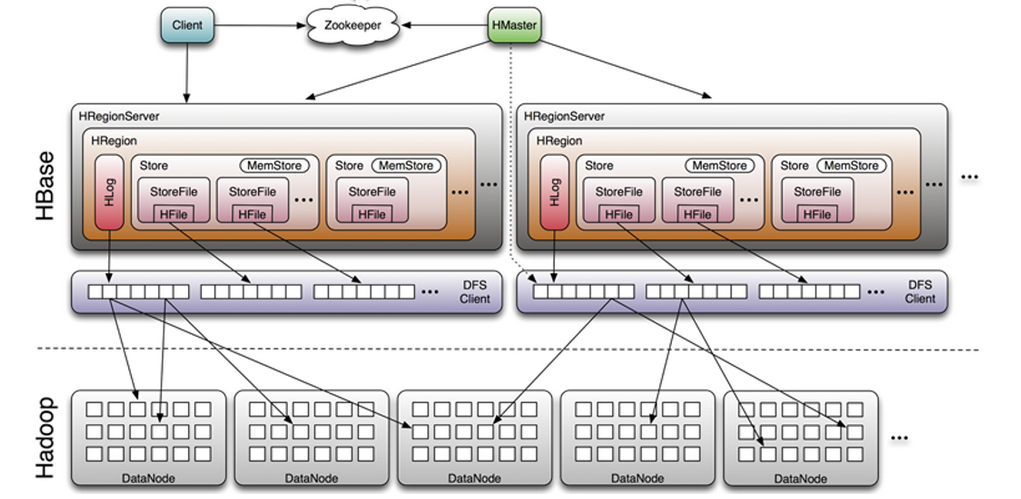
1)Client
可以通过 HBase 提供的各式语言API 库访问集群。
API 库也会维护一个本地缓存来加快对 HBase 对访问,比如缓存中记录着 Region 的位置信息。Client 可直接连接 RegionServer,并通信获取 HBase 中的数据。
2)Master
主要为各个 RegionServer 分配 Region,负责 RegionServer 的负载均衡,管理用户对于 Table 对 CRUD 操作。
依赖于Zookeeper,可允许多个Master节点共存。只有一个Master提供服务,其他Master节点备用。工作Master节点宕机时,备用Master接管集群
3)Region Server
- RegionServer:一个RegionServer包括多个Region。
- RegionServer 的作用只是管理表格,以及实现读写操作。
- 维护 Region,处理对这些 Region 的IO 请求,负责切分在运行过程中变过大的 Region。
- Region:Region是真实存放HBase数据的地方,是HBase可用性和分布式的基本单位。
- 如果表格很大,表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。
4)Zookeeper
- Zookeeper中存储了Meta表的地址和Mater的地址,HRegionServer也会注册到Zookeeper
- Mater通过 Zookeeper随时可以感知到各个HRegionServer的机器情况
- Zookeeper可以避免Master的单点问题
3 HBASE基本概念
- Row Key:表中记录主键,字典序
- 将经常读取的行存储到一起,提高读取的效率
- 好好设计行键,避免写热点
- Column Family:列族,表schema一部分,列的前缀
- 创建完之后修改成本很大
- 一个列族包含的所有列在物理存储上都是在同一个底层的存储文件当中
- Key 和 Version number在每个列族中均有一份。
- Column Qulifimer:在列族下辅助定位单元格
- Column:列,属于某个列族,可动态添加
- Version Number:默认是时间戳,降序排列
- 一个单元格里面是数据是按照版本号降序的。也就是说最后写入的值会被最先读取。
- Value(Cell):由(row key, column, Version)唯一确定,字节码

4 HBASE物理模型
每个列族存储在HDFS上的一个单独文件中,空值不会被保存。
- 多级索引:HBase为每个值维护了多级索引,即:<Row Key, Column Family, Column Qulifimer, timestamp>。
- Region:表在行的方向上分割为多个Region
- 一个 Region 存一行的所有列,由一个或多个 Store 组成,每个 Store 只存储一个 Column Family 的数据
- Region 是 Hbase 中分布式存储和负载均衡的最小单元,不同 Region 分布到不同 RegionServer 上
- Region按大小分割,随着数据增多,会分成两个新的Region
- HLog:预写日志,每个 Region Server 一个 HLog 实例
- Store:一个 Store 其实就是一个列族。
- 每个 Store 是由一个 memStore 和 0 个或者多个 storeFile 组成
- MemStore:存放在内存中
- StoreFile:存储在HDFS上,是对 HFile 的一层封装
5 工作原理
- Client 通过 Zookeeper 找到对应 Region Server
- 更新操作先记录到 HLog
- 然后写入 Store 的 MemStore
- MemStore 超过阈值后,持久化为 StoreFile
- StoreFile 写入 HDFS 的 HFile