参考:
- Cassandra vs. HBase: twins or just strangers with similar looks?[Jun 19, 2018]
- HBase vs Cassandra – Which One Is Better (Infographics)[Feb 16, 2018]
一、对比总结
- Cassandra的弱点是数据一致性,而HBase的弱点是数据可用性。
- 都擅长处理时间序列数据,都具有线性可伸缩性。
- 都不适用于经常进行数据删除和更新。
1)HBase
HBase 设计目的是处理数据湖、数据仓库中的冷数据
- 擅长处理文本分析和基本数据分析(通过协处理器)
- Base只提供数据管理,不负责存储,有外部依赖。查询语言需重新学习。
- 所有数据都存储在HDFS。
- 使用Zookeeper管理服务器状态,元数据的位置。
- 适合已经投资了Hadoop基础设施和技能时使用。
- 擅长读(因为其没有数据重复)
2)Cassandra
Cassandra 设计目的是支持“always-on”的在线Web和移动应用程序
- 擅长处理复杂分析、实时分析。
- Cassandra是数据存储和数据管理工具,“自给自足”。有类似SQL的CQL。
- 擅长写(直接hash,不需要经过Zookeeper)
- 能够在不同国家/地区创建数据中心并使其保持同步运行。
- 如果将 Cassandra 与 Spark 结合使用,也可以获得良好的扫描性能。
3)特性对比
| 特性 | HBase | Cassandra |
|---|---|---|
| CAP | CA,一致性&可用性 | AP,可用性&分区容错性 |
| 协处理器 | 有 | 无 |
| 再平衡 | 在群集中提供自动再平衡 | 不支持集群整体再平衡 |
| 架构模型 | 主从架构模型 | 双活节点模型 |
| 数据库基础 | Google BigTable | Google Bigtable&Amazon DynamoDB |
| 单点故障 | 存在,当主节点不可用时 | 没有,所有节点相等 |
| 灾难恢复 | 支持,如果配置了两个主节点 | 支持,所有节点相等 |
| HDFS兼容性 | 兼容 | 不兼容 |
| 一致性 | 强一致性 | 弱一致性 |
二、数据模型
1)HBase
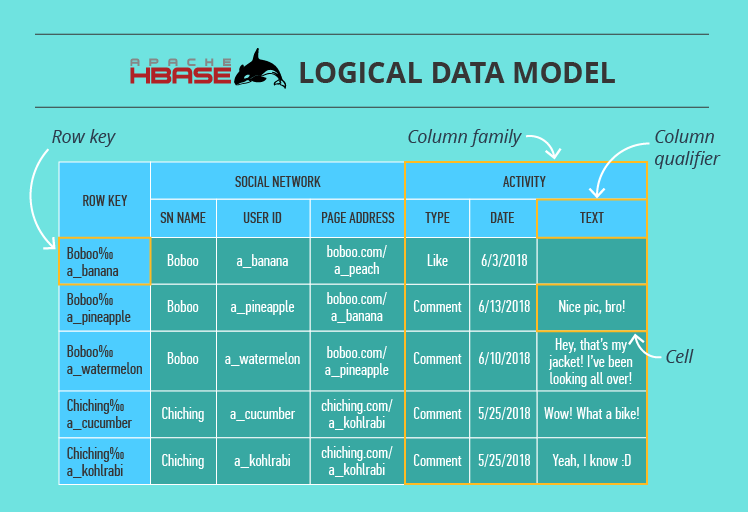
- cell:数据存储基本单位。包含 value 和 timestamp。
- column:cell的集合。在 column family 和 column qualifier 之下。
- column qualifier:column family之下,更好地定位数据。
- column family:column的集合
- row key:保存对列族数据的唯一值
- table:column family的集合
在 table 中,数据按一列行键字典顺序分区。行键的设计至关重要,用以确保高效的数据查找。
2)Cassandra
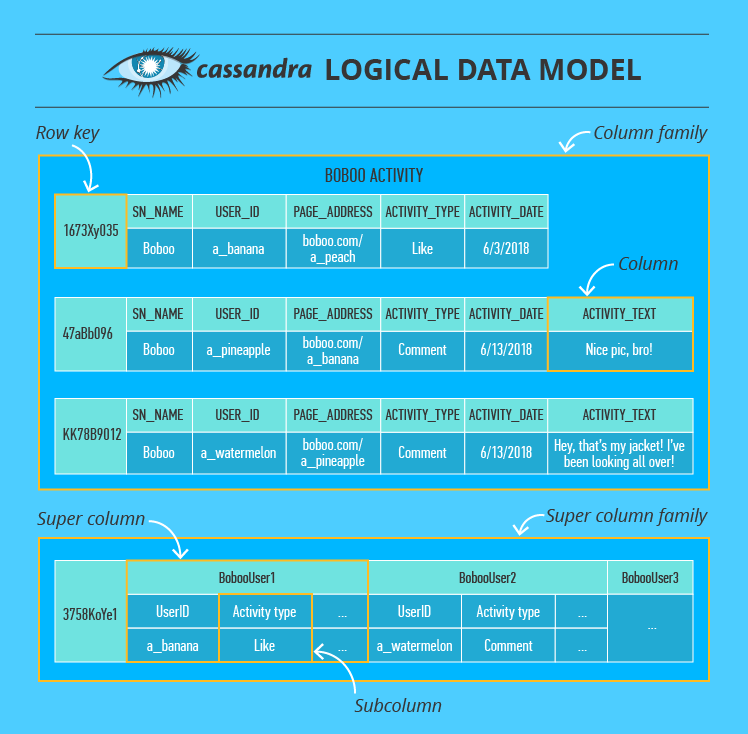
- column family:按行储存column
- row key:主键
- column:数据存储基本单位。包含name/key, value, timestamp
- super column:特殊列,value可包含多个子列
在 cluster 中,数据按多列主键的hash值分区,并被分配到 token 比其hash值大的结点,再根据复制因子备份到相应结点。
3)数据模型对比
术语相同,含义不同。
- Cassandra 的
column类似 HBase 的cell。 - Cassandra 的
column family类似 HBase 的table。 - Cassandra 的
super column类似 HBase 的column qualifier,但前者最少2个子列,后者只能一个。
//todo
另外,Cassandra 允许一个主键包含多列,而 HBase 只有单列行键,并让开发者设计行键。同时,Cassandra 的主键包括分区键和聚类列,分区键里仍能包含多列。
三、架构
1)单点失败
- Cassandra 是去中心架构,没有单点失败。
- HBase 是中心化架构,存在单点失败。
2)可用性
- Cassandra 始终可用。
- 通过群集中标识的多个种子节点互相通信,确保高可伸缩性和可用性
- HBase 客户端可以不经主节点与从节点直接联系,在主节点挂掉之后集群还能工作一段时间。
- 通过备用主节点取代故障的主节点,确保高可伸缩性和可用性
3)一致性
- Cassandra具有一致性问题:为确保可用性,Cassandra 会复制数据
- HBase具有强一致性:只将数据写入一个地方并且始终知道在哪里找到它(数据复制在HDFS中“外部”完成)。
4)节间通信
- Cassandra集成Gossip协议。数据在节点间复制。
- HBase依赖于外部Zookeeper。一个节点作为主节点,所有其他节点通过其获取数据。
5)事务
支持轻量级事务
- Cassandra事务机制:“Compare and Set”和“行级写隔离”。
- HBase事务机制:“Check and Put”和“Read-Check-Delete”。
6)查询语言
HBase shell 和 Cassandra shell都基于JRuby Shell。
- Cassandra有一个类似SQL的特定查询语言CQL。比HBase具有更多功能。
- HBase查询语言是一种需要学习的自定义语言
7)功能
- Cassandra 的架构支持数据管理和存储。
- 没有协处理器
- 支持有序分区
- 不支持基于范围的行扫描
- HBase的架构仅用于数据管理。
- 有协处理器,用于执行用户代码。
- 不支持有序分区
- 支持触发器
- 支持基于范围的扫描
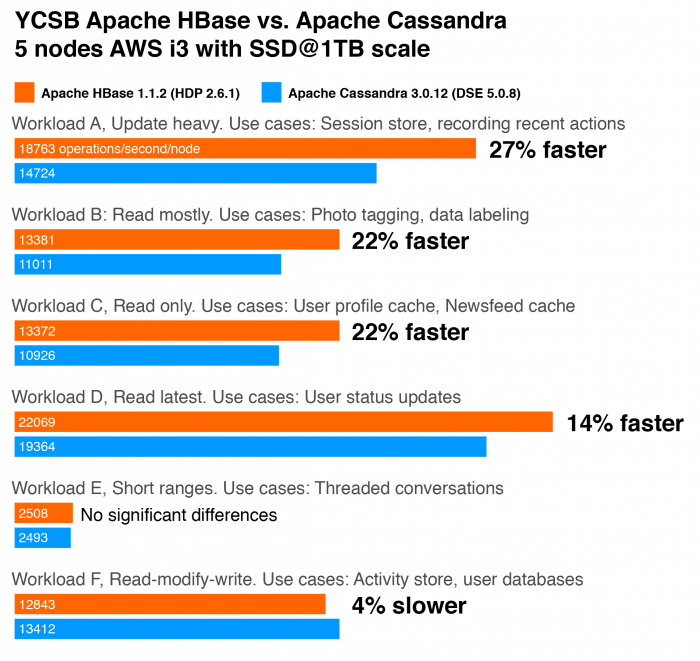
四、性能
1)写
Cassandra 更擅长写。
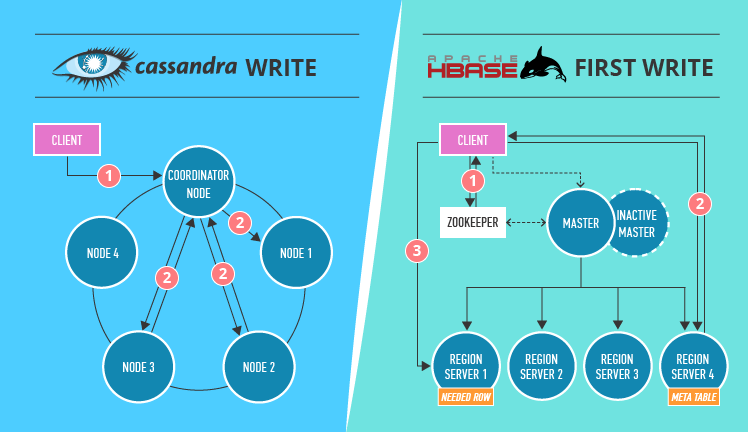
Cassandra 基于一致性hash,HBase 依赖Zookeeper
- HBase 写入流程:
- 首先,客户端向Zookeeper“询问”具有meta表的服务器(meta表包含有关集群中所有表位置的信息)。
- 然后,客户端“询问”meta表服务器,“谁”存储它需要写入的实际表。
- 最后,客户端才会将数据写入所需的位置。
- 如果相同写入、读取经常发生,信息会缓存。但是如果将表移动了,则需再次执行完整轮次。
- 在 HBase 内部写入结束后(缓存的数据被刷新到磁盘),HDFS 也需要时间来存储数据。
2)读
HBase 更擅长读。
- HBase 擅长大量快速一致的读取
- 只在一台服务器上写入,读取时无需比较不同节点的数据版本。
- HBase需要从HDFS取数据。但对于所有频繁访问的HDFS数据都有缓存,对所有其他数据的近似“地址”还应用了布隆过滤器,可加速数据检索。
- HBase和HDFS的索引系统是多层的,比Cassandra的索引更有效。
- Cassandra 只擅长主键已知的针对读取,不保证一致。
- 在要求扫描和一致性时,Cassandra 比 HBase 慢。