官方文档 (不完整,很多todo)
1 Cassandra简介
- Cassandra 是一种分布式非关系型数据库,具有高性能、可扩展、无中心化、高可用性、无单点故障等特征。
- 以 Amazon 完全分布式的 Dynamo 数据库作为基础,结合 Google BigTable 基于列族(Column Family)的数据模型,实现 P2P 去中心化的存储。
- 在 CAP 原则上,HBase 选择了 CP,Cassandra 则更倾向于 AP,所以在一致性上有所减弱。适合实时事务处理和提供交互型数据。
特性
- 对等分布式:P2P架构,无中心节点,集群中每一个节点都具有相同地位。
- 分布式管理:基于Gossip协议,允许节点相互通信并检测集群中的任何故障节点。
- 放置数据:分布式 hash 表,每个节点都对应一个 hash 值,用于存储一定范围内的分区键的数据。
- 可插拔的分区:可添加或者删除节点,但是保证数据不会丢失。
- 可配置的放置策略:可配置不同的策略用于分布副本。
- 可配置的一致性:对读写操作均可配置不同的一致性级别。
2 存储过程
用户可以使用Cassandra查询语言(CQL)通过其节点访问Cassandra。
写操作
- 将新记录写入CommitLog;
- 将新纪录写入Memtable;
- 达到阈值, 将Memtable中的数据刷入到磁盘上的SSTables, 清空JVM Heap和CommitLog;
- 达到阈值, 将SSTables压缩合并.

读操作
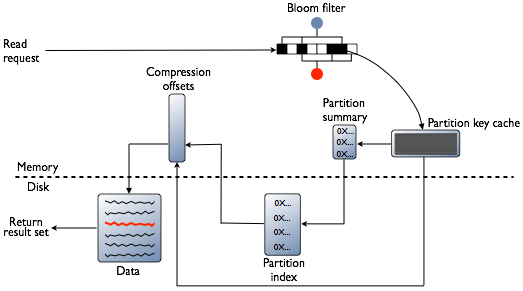
读取时,Cassandra 需要结合 memtable 和可能多个 SSTable 的结果。
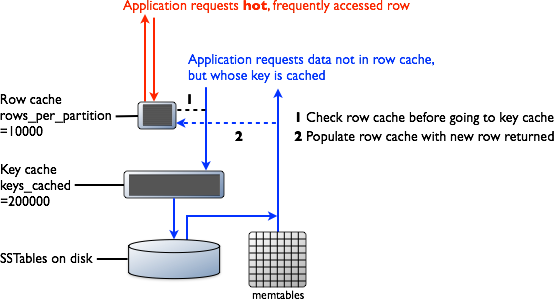
- 检查 memtable。
- 在 Memtable 中找到 Key 的 value
- 检查 Row Cache
- 若在缓存中找到 value,返回。
- 若缓存中没有找到,查找每个 SSTable 的 BloomFilter,看是否在该 SSTable 中。
- 若在该SSTable
- 查找 SSTable 的 Partition Summary。确定 Key 在 Partition Index 中的大概位置。
- 查找 Partition Index 中 Key 位于 SSTable 中的偏移量。
- 查找完成之后将 Key 位于每个 SSTable 中的偏移量放入 Key Cache 中。
- 合并 SSTable 与 Memtable 数据
- 在各个 SSTable 中找到 Key 的所有 value,再在 Memtable 中找到 Key 的 value。
- 对所有的 value 进行合并操作,原则是取时间戳最新的数据作为正确地数据。
- 将合并后的数据返回给 Coordinator 并且将 Key 及其 value 放入 Row Cache 缓存中。
Read request flow
Row cache and Key cache request flow
3 数据一致性
Cassandra 的一致性是可配置调整的:
- 读不旧于写一致性(Read-your-writes consistency):使用者读到的数据,总是不旧于自身上一个写入的数据。
- 会话一致性(Session Consistency):使用者在一个会话中才保证读写一致性,启动新会话后则无需保证。
- 单读一致性(Monotonic Read Consistency):读到的数据总是不旧于上一次读到的数据。
- 单写一致性(Monotonic Write Consistency):写入的数据完成后才能开始下一次的写入。
- 写不旧于读一致性(Writes-follow-reads Consistency):写入的副本不旧于上一次读到的数据,即不会写入更旧的数据。
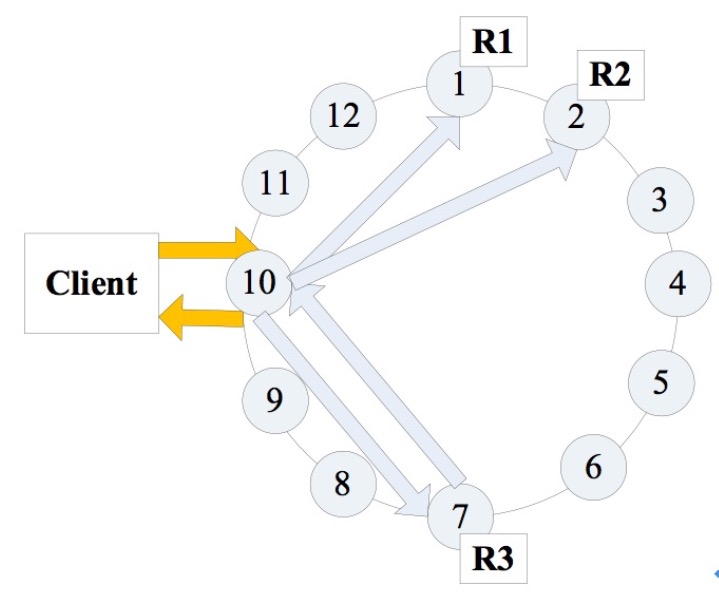
4 客户端
客户端连接到某一节点发起读或写请求时,该节点充当客户端应用于拥有相当数据的节点数据的节点间的协调者,用以根据集群配置确定环(ring)中的哪个节点应当获取这个请求。