LinkedHashSet 仅对 LinkedHashMap做了一层包装,实现相同。LinkedHashSet 里面有一个LinkedHashMap(适配器模式)。
1 总体介绍
LinkedHashMap 有序,非同步,允许null键null值,是由linkedList增强的HashMap。
继承于HashMap,采用双向链表的形式将所有entry连接起来,保证顺序。
排序方式有两种:
- 根据写入顺序排序。
- 根据访问顺序排序。
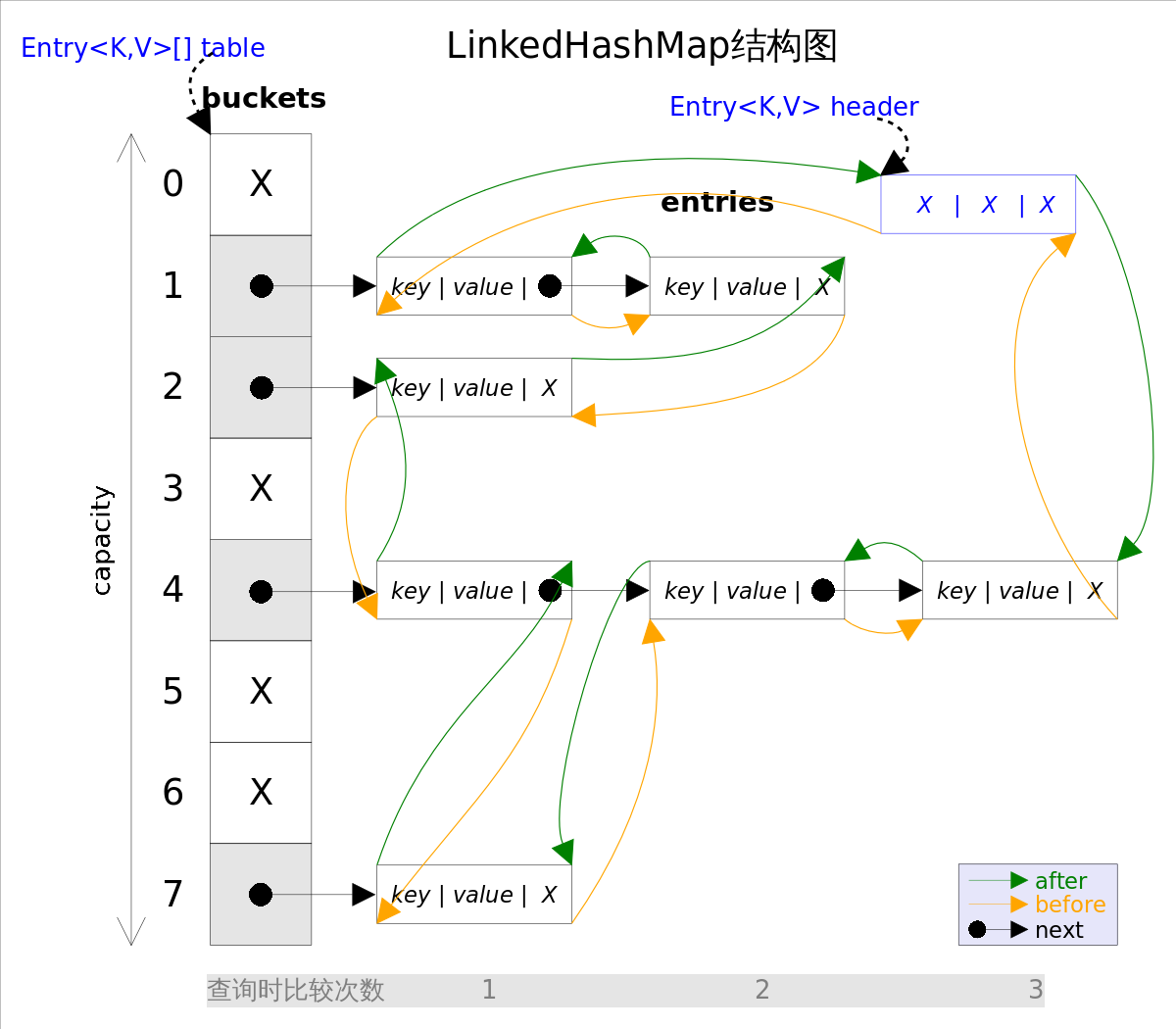
1.1 数据结构
private transient Entry<K,V> header;
private final boolean accessOrder;
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
}
- 多了一个
header,是这个双向链表的头结点,一个哑元 Entry继承于HashMap的Entry,并新增了上下节点的指针,形成双向链表。- 还有一个
accessOrder成员变量,默认是false,默认按照插入顺序排序,为true时按照访问顺序排序
1.2 构造方法
public LinkedHashMap() {
super();
accessOrder = false;
}
调用的 HashMap 的构造方法, 实现init():
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
其实也就是对 header 进行了初始化。
2 方法剖析
2.1 get() 方法
重写 HashMap 的 get() ,多了一个判断
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
//多了一个判断
e.recordAccess(this);
return e.value;
}
判断是否是根据访问顺序排序,如果是则需要将当前这个 Entry 移动到链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
//删除
remove();
//添加到头部
addBefore(lm.header);
}
}
2.2 put() 方法
插入有两重含义:
- 从 table 的角度看,新的 entry 需要插入到对应的 bucket 里,当有哈希冲突时,采用头插法将新的 entry 插入到冲突链表的头部。
- 从 header 的角度看,新的 entry 需要插入到双向链表的尾部。
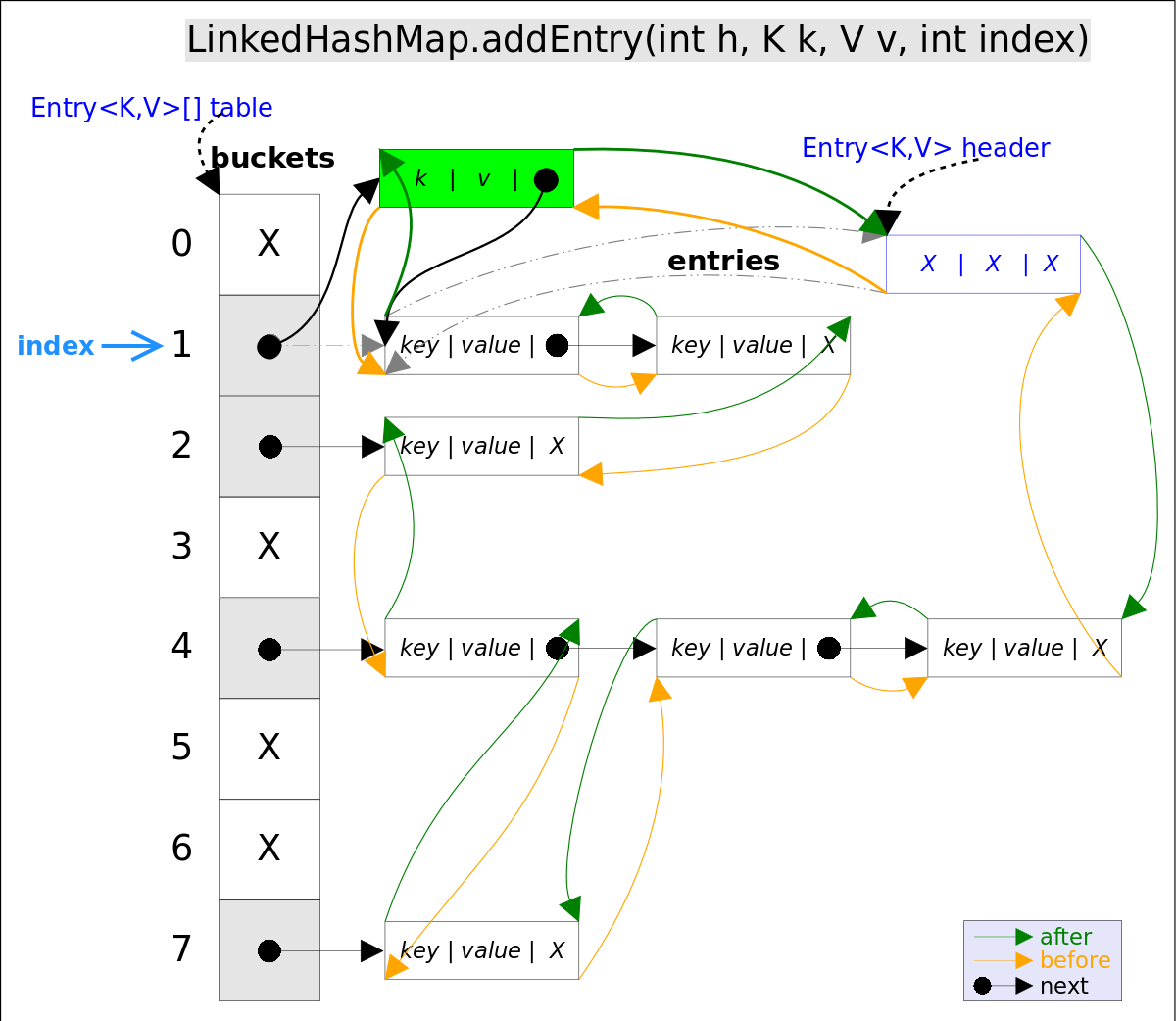
调用了 HashMap 的实现,并判断是否需要删除最少使用的 Entry(默认不删除)
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
将新增的 Entry 加入到 header 双向链表中
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
//就多了这一步
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
写入到双向链表中
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
2.3 remove() 方法
调用 removeEntryForKey() ,先找到 key 值对应的 entry ,然后删除该 entry (修改链表的相应引用)。
删除也有两重含义:
- 从 table 的角度看,需要将该 entry 从对应的 bucket 里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。
- 从 header 的角度来看,需要将该 entry 从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
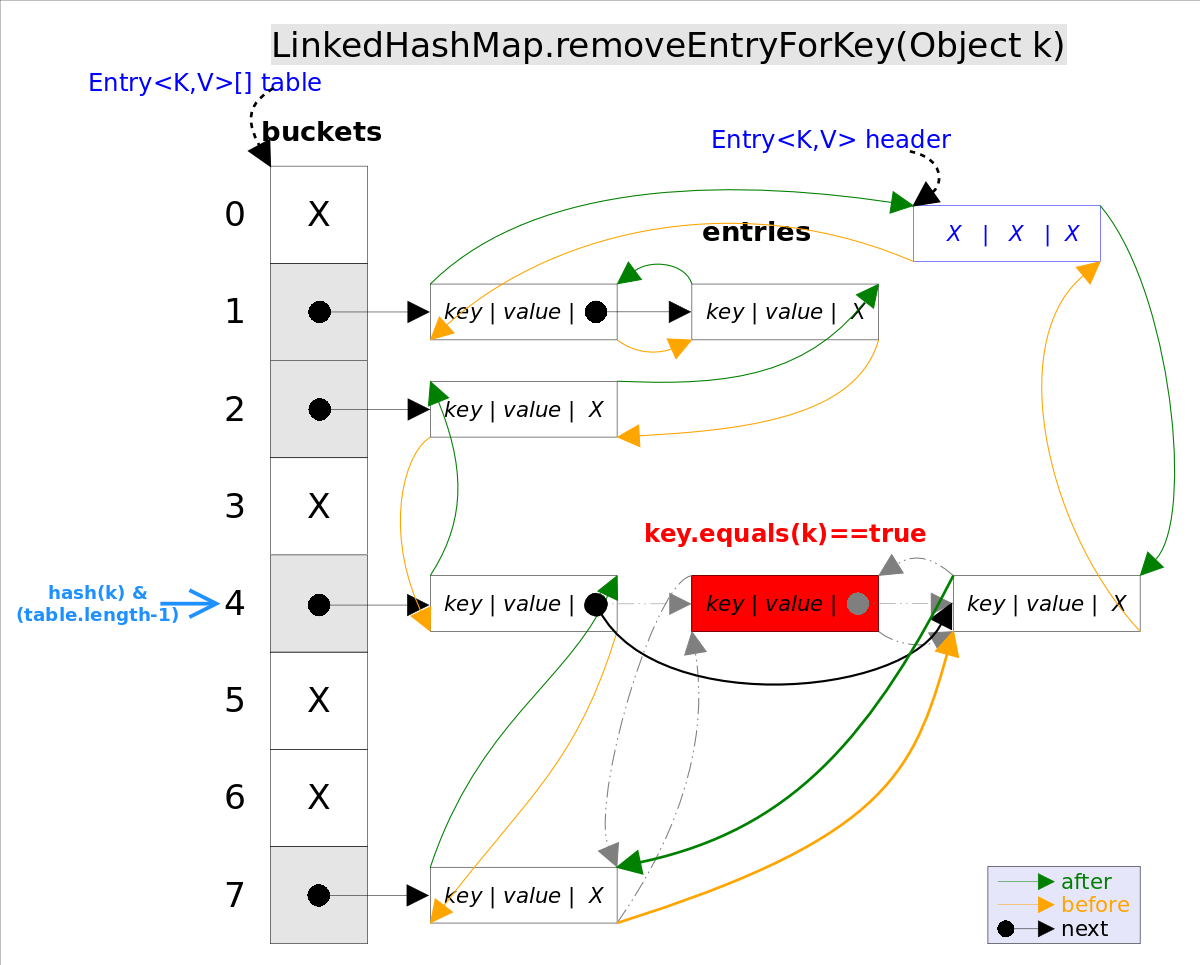
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++;
size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e)
table[i] = next;
else
prev.next = next;
// 2. 将e从双向链表中删除
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
private void remove() {
before.after = after;
after.before = before;
}
2.4 clear() 方法
只需要把指针都指向自己即可,原本那些 Entry 没有引用之后就会被 JVM 自动回收。
public void clear() {
super.clear();
header.before = header.after = header;
}
3 LinkedHashMap 经典用法 LRU
LinkedHashMap 可以轻松实现一个采用了 FIFO 替换策略的缓存 - LRU(Least Recently Used)。
LinkedHashMap 有一个子类方法 boolean removeEldestEntry(Map.Entry<K,V> eldest) ,决定是否要删除“最老”的 Entry,如返回 true ,就删除。每次插入新元素的之后,都会询问 removeEldestEntry()。
只需在子类中重载该方法,当元素个数超过一定数量时让 removeEldestEntry() 返回true,就能够实现一个固定大小的FIFO策略的缓存。
示例代码如下:
/** 一个固定大小的FIFO替换策略的缓存 */
class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当Entry个数超过cacheSize时,删除最老的Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}