HashSet仅对HashMap做了一层包装,实现相同。HashSet里面有一个HashMap(适配器模式)。
Hashtable与HashMap大致相同,但Hashtable是同步的,并且不允许使用 null 。
1 HashMap
1.1 总体介绍
基于哈希表,实现了Map接口。允许null值null键,非同步,无序。
哈希表有两种实现方式,开放地址方式和冲突链表方式。
HashMap采用的是冲突链表方式(数组和链表)。
1)JDK1.7

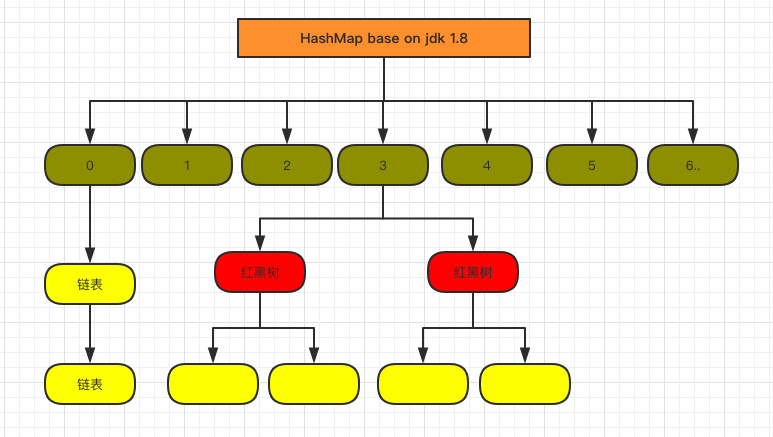
2)JDK1.8
当 Hash 冲突严重时,链表越来越长,查询效率越来越低;时间复杂度为 O(N)。
JDK1.8 优化了查询效率,若链表数超过阈值(默认为8),链表转为红黑树,时间复杂度O(logn)。若链表数降到阈值(默认为6)以下,又恢复成链表。
3)重要参数
有两个重要的参数:
- 初始容量
inital capacity = 默认16,必须是2^n,最大1 << 30 - 负载因子
load factor = 默认0.75f
当 entry 的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。
1.2 方法剖析
1)get()
调用 getEntry(Object key) 得到相应的 entry ,然后返回 entry.getValue()。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];//得到冲突链表
e != null;
e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- 首先通过 hash() 函数得到哈希值 hash
- 通过哈希值 hash 得到对应 bucket 的下标
h & (length-1) 等价于 h%length,因为length是2^n,length-1 就是二进制低位全是 1,跟 h 相与会将哈希值的高位全抹掉,剩下的就是余数了。static int indexFor(int h, int length) { return h & (length-1); } - 然后依次遍历冲突链表,通过 key.equals(k) 方法来判断是否是要找的那个 entry 。

2)put()
首先 get(),如已含则直接返回。否则通过addEntry插入新的 entry。
- 1.7
- 头插法
- 在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题
- 初始化单独函数
- hash 值计算扰动 9 次
- 无冲突存数组,冲突存单链表
- 扩容时需要重新计算哈希值和索引位置
- 头插法
- 1.8
- 尾插法:插入链表尾部、红黑树
- 在扩容时会保持链表元素原本的顺序
- 不会出现逆序、环形链表死循环问题
- 初始化继承在扩容函数
- hash 值计算扰动 2 次,变少
- 无冲突存数组,冲突存单链表,链表长度大于 8 转为红黑树,小于 6 转回来
- 扩容时不重新计算哈希值,原位置或原位置加旧容量
- 尾插法:插入链表尾部、红黑树
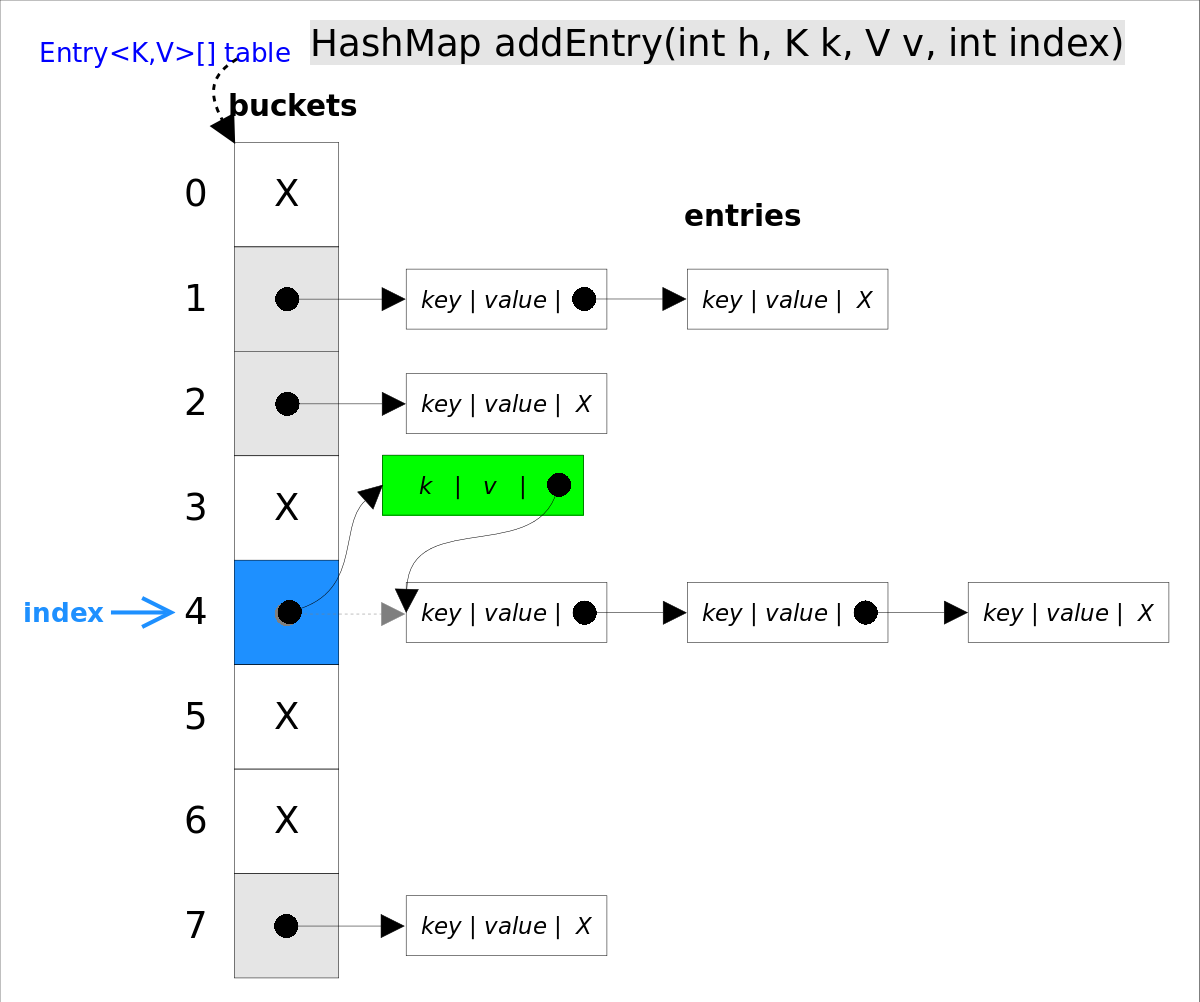
void addEntry(int hash, K key, V value, int bucketIndex) {
//threshold=The next size value at which to resize (capacity * load factor).
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//在冲突链表头部插入新的entry
createEntry(hash, key, value, bucketIndex);
}
扩容
计算新容量,新建一数组
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));//转移
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
转移
重新哈希到新数组
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {//重新哈希
e.hash = null == e.key ? 0 : hash(e.key);
}
//将此列移到新表的新列里
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
2 HashSet
前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
3 Hashtable
单一锁,put,get 都同步,效率低